I have a reader '2005Unique' and a writer '2005Gridded'. There is also a reader called 25kGrid, all .shp.
There are a few attributes coming from 2005Unique that I want '05' appending to the end of (for reasons of inter-year comparison further down the line). Eg Land to Land05 and Area to Area05 etc etc. Originally in my tests I simply renamed the attributes in the writer, stuck 05 on the end of them, as I was only testing data with this one year.
Now i'm coming to run the data across 5 year files, 05 to 09. I am looking to set up the dynamic schema to read each year file one by one and write them one by one but obviously i cant just leave the writer attributes with 05 as a suffix, it has to change to 06 when the 2006 stuff runs through.
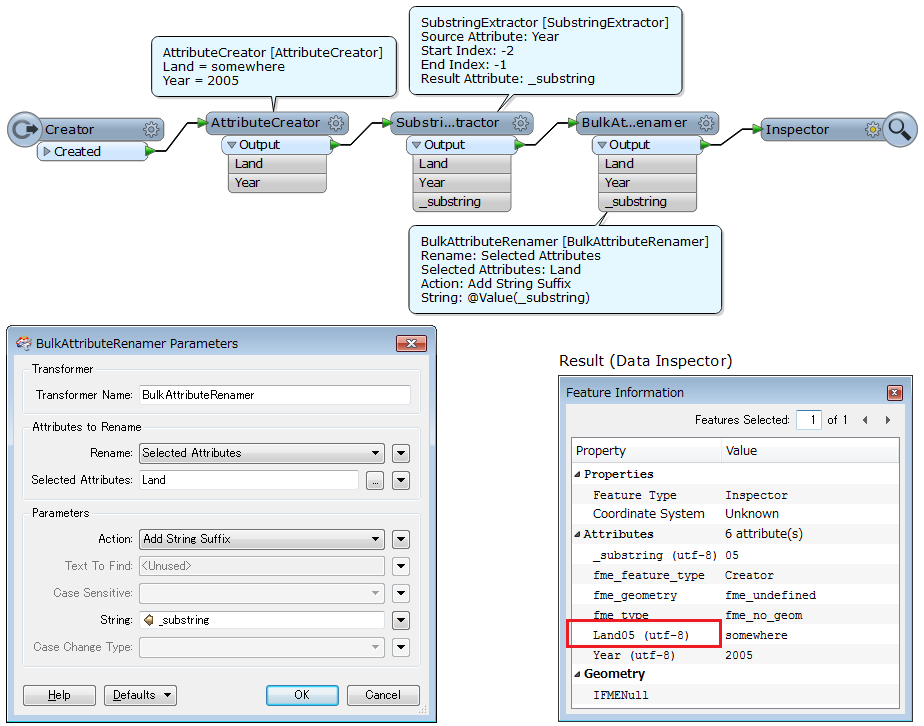
So i set up a SubstringExtractor pointing at the fme_basename (also tried the parameter $Sourcedataset_Shape) and told it to extract characters 2 and 3, i.e '05', and set it to '_substring'. Then, in my BulkAttributeRenamer, i select the required attributes, add a string suffix and then set string to '_substring'.
2 issues:
1 - why arent the attributes taking on the suffix? they remain the same. If i manually type 05 then they will change but thie way described above makes no impact. they dont change.
2 - In my writer, how will the writer attributes be dynamic? How will they change as the file name, and thus the substring suffix, changes? Is this sorted by the dynamic schema?
thanks a lot