
Accents in attributes
- April 4, 2013
- 24 replies
- 654 views
- Upvote
- Share
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
24 replies

 +22
+22- Safer
- April 4, 2013

The string searcher or the string pair replacer are a few options to consider.

 +25
+25- Supporter
- April 4, 2013


- April 4, 2013

Hi,
here is a more dynamic solution using a PythonCaller. Modify "attribute_list" (line 16, case sensitive) to include the names of the attributes you want to be checked for accents:
import fmeobjects
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(unicode(char))
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
return ud.lookup(desc)
def removeAccents(feature):
attribute_list = ("name", "type", "state") # Modify as needed
for attrib in feature.getAllAttributeNames():
if attrib in attribute_list:
value = feature.getAttribute(attrib)
if value:
value = unicode(value)
new_value = ''.join([rmdiacritics(char) for char in value])
feature.setAttribute(attrib, new_value)
- Attribute(encoded: utf-8): `name' has value `François'
- Attribute(encoded: utf-8): `state' has value `Tørst'
- Attribute(encoded: utf-8): `type' has value `Salé'
- Attribute(encoded: utf-16): `name' has value `Francois'
- Attribute(encoded: utf-16): `state' has value `Torst'
- Attribute(encoded: utf-16): `type' has value `Sale'
- April 4, 2013
here is a more dynamic solution using a PythonCaller. Modify "attribute_list" (line 16, case sensitive) to include the names of the attributes you want to be checked for accents:
-----
import fmeobjects import unicodedata as ud def rmdiacritics(char): ''' Return the base character of char, by "removing" any diacritics like accents or curls and strokes and the like. ''' desc = ud.name(unicode(char)) cutoff = desc.find(' WITH ') if cutoff != -1: desc = desc[:cutoff] return ud.lookup(desc) def removeAccents(feature): attribute_list = ("name", "type", "state") for attrib in feature.getAllAttributeNames(): if attrib in attribute_list: value = feature.getAttribute(attrib) if value: value = unicode(value) new_value = ''.join([rmdiacritics(char) for char in value]) feature.setAttribute(attrib, new_value)
-----
You can also download the code here, in case the forum mangles the indents.
Example values before the PythonCaller:
Attribute(encoded: utf-8): `name' has value `François' Attribute(encoded: utf-8): `state' has value `Tørst' Attribute(encoded: utf-8): `type' has value `Salé'
After the PythonCaller:
Attribute(encoded: utf-16): `name' has value `Francois' Attribute(encoded: utf-16): `state' has value `Torst' Attribute(encoded: utf-16): `type' has value `Sale' David
- Author
- April 4, 2013
THis is exactly what i am looking for. However i am new with python scripts, and still stuck in FME2011 so it looks like this code will work with 2012. Any suggestions on how to implement in 2011?
Thanks!
- April 4, 2013
seems like a good opportunity to learn some Python, then :-)
Basically, replace
- "fmeobjects" with "pyfme"
- "getAttribute" with "getUnicodeString"
- "setAttribute" with "setUnicodeString"
Untested, but I think that should be enough to get it running, I hope.
Also, take a look at the pyfme API doc in <fmedir>\\\\fmeobjects\\python\\apidocs\\index.html -- in particular the methods under FMEFeature.
David
- Author
- April 4, 2013
One last (and probably dumb) question. What symbol is used in the caller?
- April 4, 2013
not a dumb question when you're not familiar with the PythonCaller :-)
You should use "removeAccents" for the PythonCaller.
Hint: it's almost always the function ("def ...") that takes a parameter called "feature", which represents each feature object passed into the function. E.g.
def <name of function>(feature):
David
- April 4, 2013
Source Attribute: Name
Replacement Pairs: É E È E Ë E Ê E Ô O Ç C Â A ï I î I
Result Attributer: Name2
- April 4, 2013
I agree, that is the most "native" FME solution, but it assumes that you're able to populate it with all the possible variants. If something isn't caught (like a sudden "Û" in your example), it will simply pass through and result in an error further down the line, where it might not be obvious what happened.
The beauty of the PythonCaller script is that it is a lot more future-proof, although it adds quite a bit of complexity, I must admit...
David
- Author
- April 5, 2013
 +1
+1- Participant
- April 5, 2013

import unicodedata def remove_accents(input_str): nkfd_form = unicodedata.normalize('NFKD', unicode(input_str)) only_ascii = nkfd_form.encode('ASCII', 'ignore') return only_ascii +1
+1- Contributor
- January 27, 2016

Hi,
here is a more dynamic solution using a PythonCaller. Modify "attribute_list" (line 16, case sensitive) to include the names of the attributes you want to be checked for accents:
import fmeobjects
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(unicode(char))
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
return ud.lookup(desc)
def removeAccents(feature):
attribute_list = ("name", "type", "state") # Modify as needed
for attrib in feature.getAllAttributeNames():
if attrib in attribute_list:
value = feature.getAttribute(attrib)
if value:
value = unicode(value)
new_value = ''.join([rmdiacritics(char) for char in value])
feature.setAttribute(attrib, new_value)
- Attribute(encoded: utf-8): `name' has value `François'
- Attribute(encoded: utf-8): `state' has value `Tørst'
- Attribute(encoded: utf-8): `type' has value `Salé'
- Attribute(encoded: utf-16): `name' has value `Francois'
- Attribute(encoded: utf-16): `state' has value `Torst'
- Attribute(encoded: utf-16): `type' has value `Sale'
Thanks David, that solution is just awesome! I used it via a Python Caller and it worked perfectly fine!!
Cheers mate!
 +7
+7- October 5, 2016
I noticed that I regularly kept comming back to this question because of the provided code by @david_r.
I figured there probably are more people using this code so I converted it to a custom transformer:
- October 5, 2016
I noticed that I regularly kept comming back to this question because of the provided code by @david_r.
I figured there probably are more people using this code so I converted it to a custom transformer:
- October 25, 2018
I noticed that I regularly kept comming back to this question because of the provided code by @david_r.
I figured there probably are more people using this code so I converted it to a custom transformer:
- October 26, 2018
Here's the same code updated for Python 3.6, @jeroenstiers
import fmeobjects
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(char)
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
return ud.lookup(desc)
def removeAccents(feature):
attribute_list = ("name", "type", "state") # Modify as needed
for attrib in feature.getAllAttributeNames():
if attrib in attribute_list:
value = feature.getAttribute(attrib)
if value:
value = str(value)
new_value = ''.join([rmdiacritics(char) for char in value])
feature.setAttribute(attrib, new_value)
- October 26, 2018
Here's the same code updated for Python 3.6, @jeroenstiers
import fmeobjects
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(char)
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
return ud.lookup(desc)
def removeAccents(feature):
attribute_list = ("name", "type", "state") # Modify as needed
for attrib in feature.getAllAttributeNames():
if attrib in attribute_list:
value = feature.getAttribute(attrib)
if value:
value = str(value)
new_value = ''.join([rmdiacritics(char) for char in value])
feature.setAttribute(attrib, new_value)
 +22
+22- Enthusiast
- October 26, 2018

Use the StringPairReplacer and paste this string below into the Replacement Pairs parameter.
Create a custom transformer and use it easily in any workbench. I've created the AccentRemover just like that :D
It's only good for french though...
à a À A â a  A ç c Ç C é e É E è e È E ê e Ê E ë e Ë E î i Î I ï i Ï I ô o Ô O ù u Ù U û u Û U ü u Ü U- October 26, 2018
Use the StringPairReplacer and paste this string below into the Replacement Pairs parameter.
Create a custom transformer and use it easily in any workbench. I've created the AccentRemover just like that :D
It's only good for french though...
à a À A â a  A ç c Ç C é e É E è e È E ê e Ê E ë e Ë E î i Î I ï i Ï I ô o Ô O ù u Ù U û u Û U ü u Ü U- October 26, 2018
Use the StringPairReplacer and paste this string below into the Replacement Pairs parameter.
Create a custom transformer and use it easily in any workbench. I've created the AccentRemover just like that :D
It's only good for french though...
à a À A â a  A ç c Ç C é e É E è e È E ê e Ê E ë e Ë E î i Î I ï i Ï I ô o Ô O ù u Ù U û u Û U ü u Ü U
 +16
+16- Supporter
- June 28, 2022
here is a more dynamic solution using a PythonCaller. Modify "attribute_list" (line 16, case sensitive) to include the names of the attributes you want to be checked for accents:
-----
import fmeobjects import unicodedata as ud def rmdiacritics(char): ''' Return the base character of char, by "removing" any diacritics like accents or curls and strokes and the like. ''' desc = ud.name(unicode(char)) cutoff = desc.find(' WITH ') if cutoff != -1: desc = desc[:cutoff] return ud.lookup(desc) def removeAccents(feature): attribute_list = ("name", "type", "state") for attrib in feature.getAllAttributeNames(): if attrib in attribute_list: value = feature.getAttribute(attrib) if value: value = unicode(value) new_value = ''.join([rmdiacritics(char) for char in value]) feature.setAttribute(attrib, new_value)
-----
You can also download the code here, in case the forum mangles the indents.
Example values before the PythonCaller:
Attribute(encoded: utf-8): `name' has value `François' Attribute(encoded: utf-8): `state' has value `Tørst' Attribute(encoded: utf-8): `type' has value `Salé'
After the PythonCaller:
Attribute(encoded: utf-16): `name' has value `Francois' Attribute(encoded: utf-16): `state' has value `Torst' Attribute(encoded: utf-16): `type' has value `Sale' David
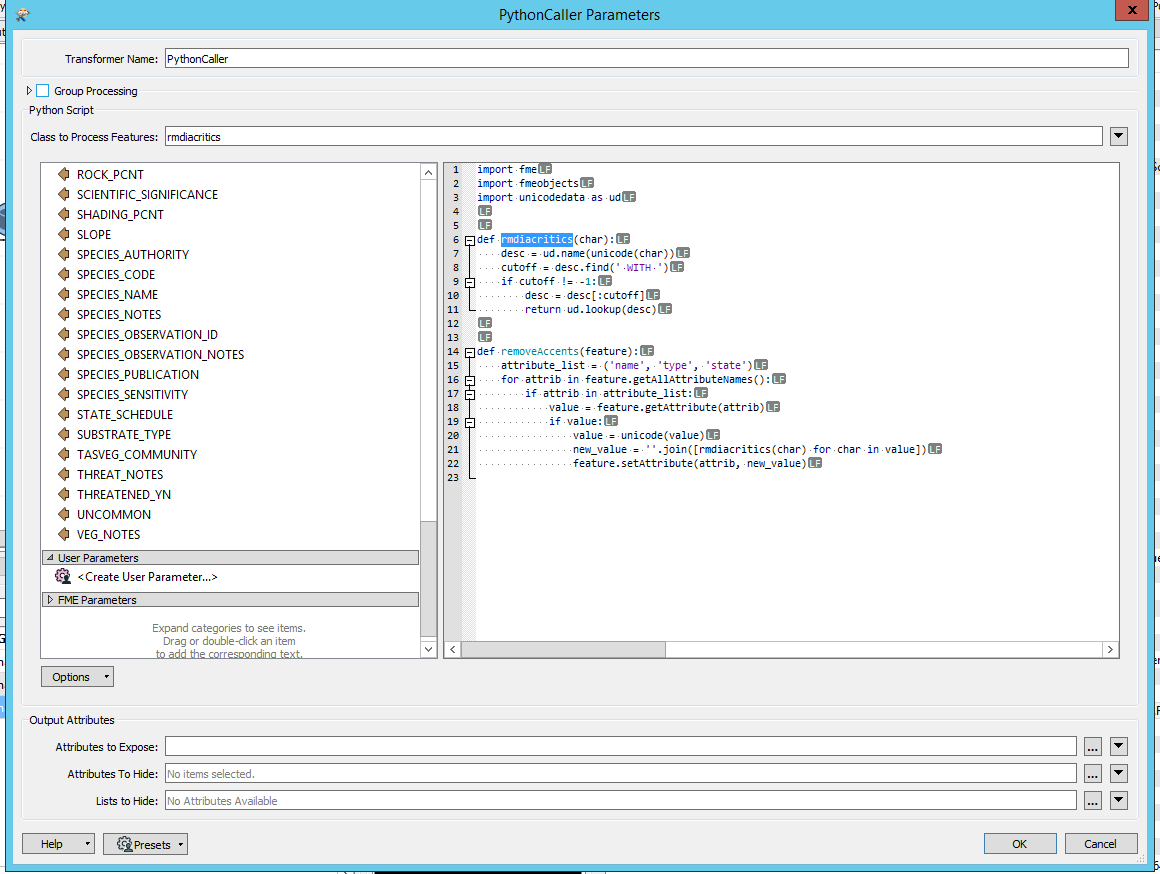
HI David,
The download file no longer appears to available.
I tried the code above up I can't get it to work, and my python isn't strong enough to see where i have gone wrong. It runs but doesn't to remove the accents :(
Here is a screen shot of my python caller
- June 29, 2022
HI David,
The download file no longer appears to available.
I tried the code above up I can't get it to work, and my python isn't strong enough to see where i have gone wrong. It runs but doesn't to remove the accents :(
Here is a screen shot of my python caller
Try using the StringDiacriticRemover from the FME Hub in stead: https://hub.safe.com/publishers/safe-lab/transformers/stringdiacriticremover
+16- Supporter
- June 29, 2022
HI David,
The download file no longer appears to available.
I tried the code above up I can't get it to work, and my python isn't strong enough to see where i have gone wrong. It runs but doesn't to remove the accents :(
Here is a screen shot of my python caller
Thanks will do :)
Community Stats
- 32,749
- Posts
- 124,195
- Replies
- 41,251
- Members
Login to the community
No account yet? Create an account
An FME Account is required to contribute
LoginEnter your E-mail address. We'll send you an e-mail with instructions to reset your password.