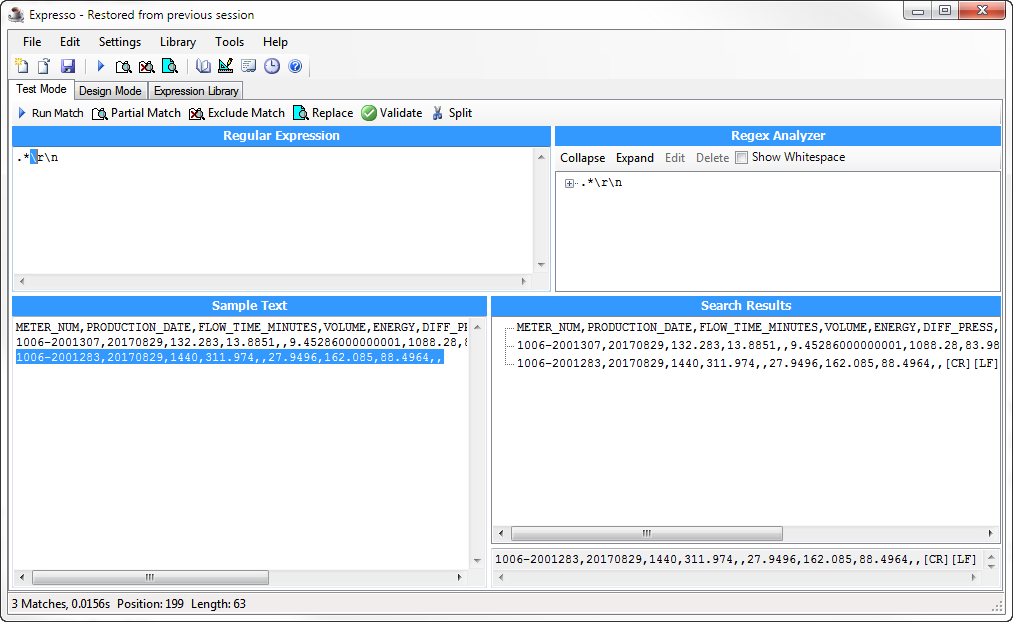
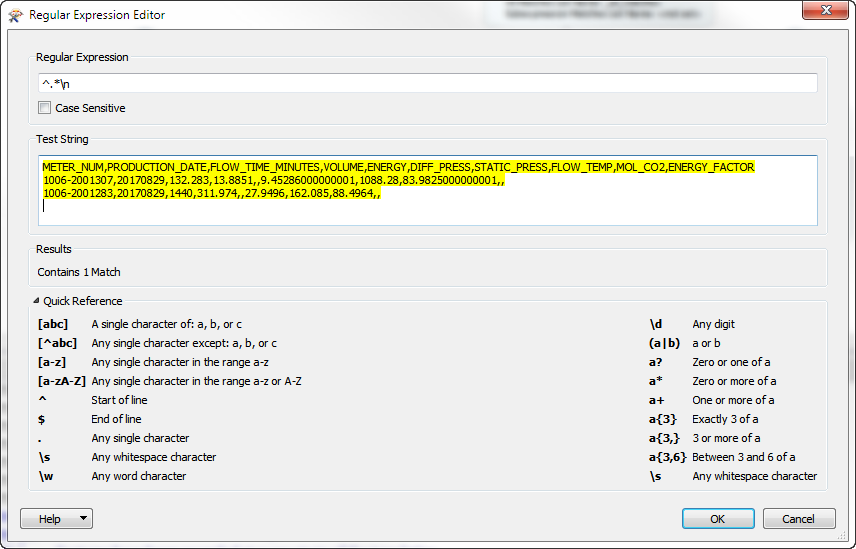
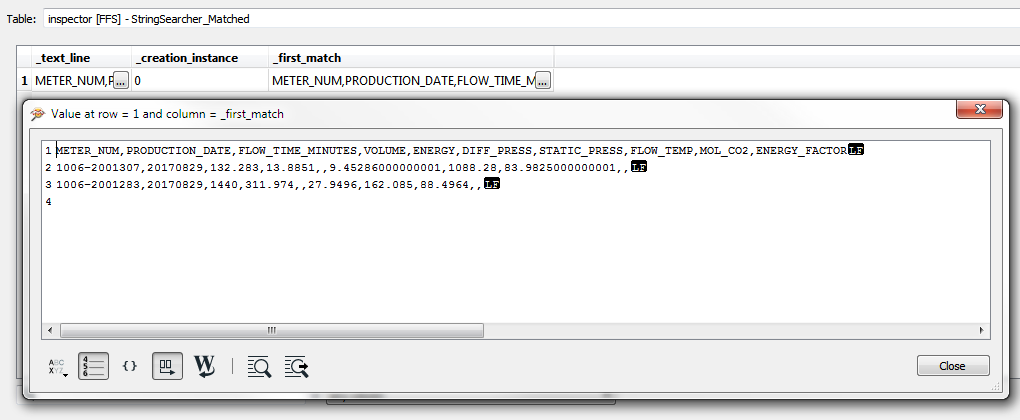
I want to find each line of the string below with a regular expression in StringSearcher that looks like this .*\\r\\n, i.e., I expect each line to end up in the all matches list produced by the StringSearcher.
METER_NUM,PRODUCTION_DATE,FLOW_TIME_MINUTES,VOLUME,ENERGY,DIFF_PRESS,STATIC_PRESS,FLOW_TEMP,MOL_CO2,ENERGY_FACTOR
1006-2001307,20170829,132.283,13.8851,,9.45286000000001,1088.28,83.9825000000001,,
1006-2001283,20170829,1440,311.974,,27.9496,162.085,88.4964,,
It works in my regex testing tool Expresso, but StringSearcher doesn't seem to recognize \\r\\n.