Hello all,
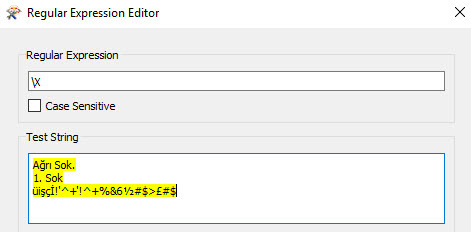
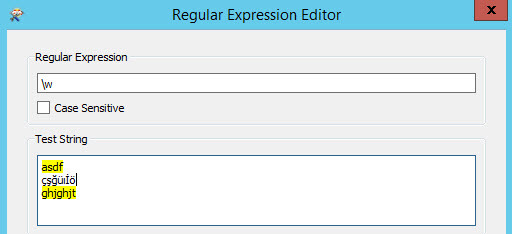
I have a problem with catching Turkish Unicode characters in StringReplacer and StringSearcher transformers. "\\w" function doesn't catch " Ç ç ? ? ? ? Ö ö ? ? Ü ü" letters. It works when I put these letters in the search bar. Also, I checked the same letters on www.regexpal.com and it didn't work too.
Is there any solution to catch these letters with "\\w"? Otherwise, I need to change these letters with other special characters which don't exist in Turkish Alphabet at the beginning and the end of the Workspace.
Thanks
Deniz