I have been using FME for some time now and am now getting into little details. My question revolves around parsing out filenames and eliminating portions of them to create a new name. This is probably elementary to many of you.
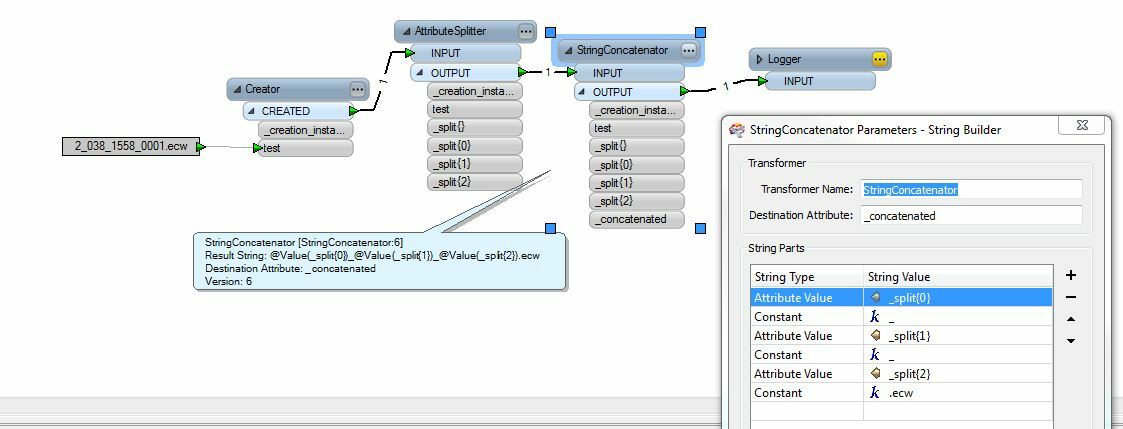
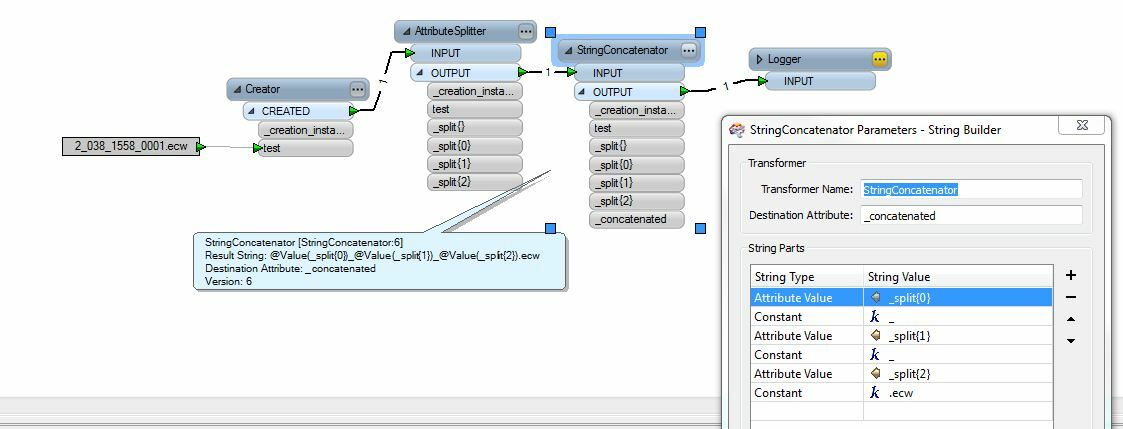
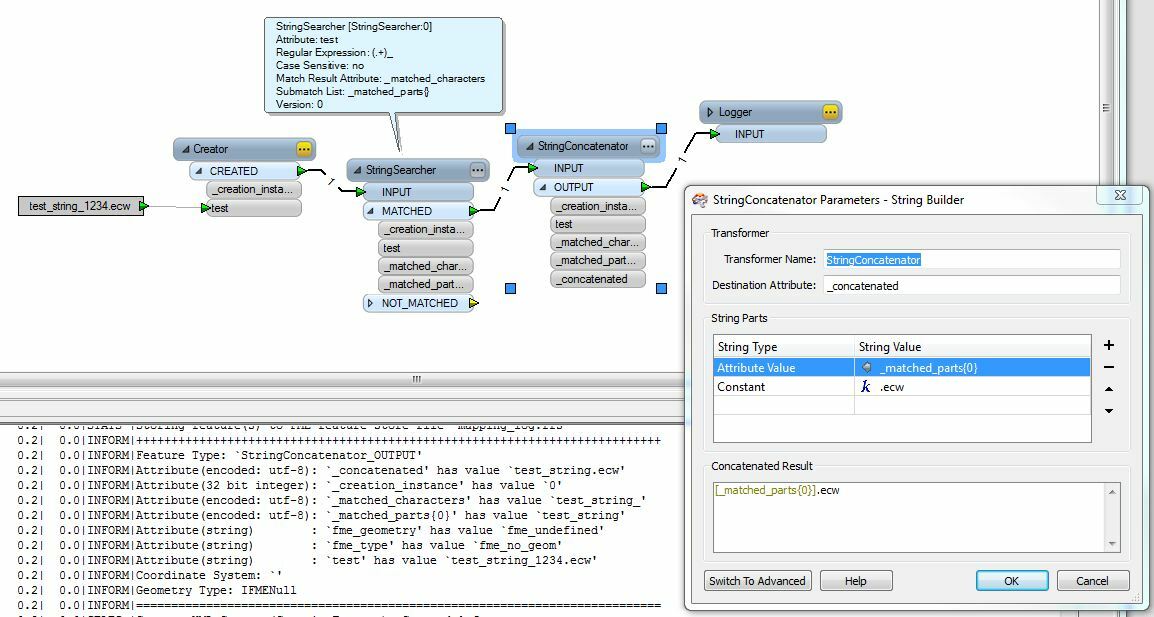
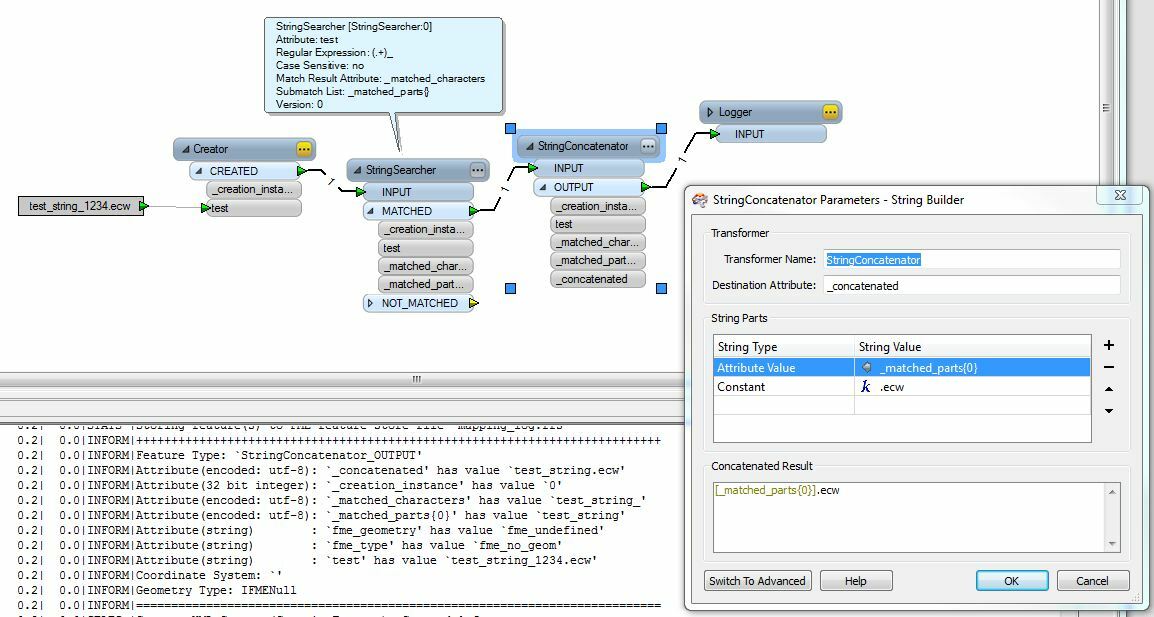
I have a name like this: 2_038_1558_0001.ecw
In this case, the number after the last underscore "_" is always an incremented value. What I want is to always eliminate the last underscore and following number and extension and have the following result:
2_038_1558
The sequential number portion is not always 4 digits. Sometimes it is 2 or 3 or 5
(2_038_1558_0001.ecw, 2_038_1558_023.ecw, 2_038_1558_00012.ecw)
Any ideas of the which transformer to use and/or the code the place within it?
Thank you for any help .