Hi All,
I could use some assistance on the problem I am facing.
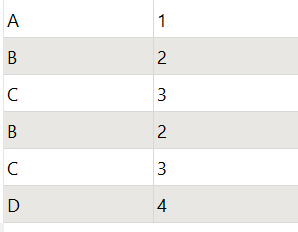
The data I have looks something like this.
R
A, B, C
?, ?, ?
I want it to look like this.
R
A
?
R
B
?
R
C
?
How would I go about doing that?
Regards,

 +4
+4Hi All,
I could use some assistance on the problem I am facing.
The data I have looks something like this.
R
A, B, C
?, ?, ?
I want it to look like this.
R
A
?
R
B
?
R
C
?
How would I go about doing that?
Regards,
Best answer by ebygomm
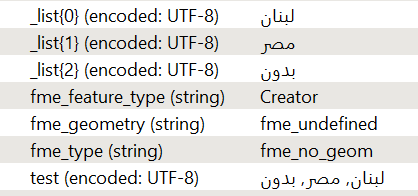
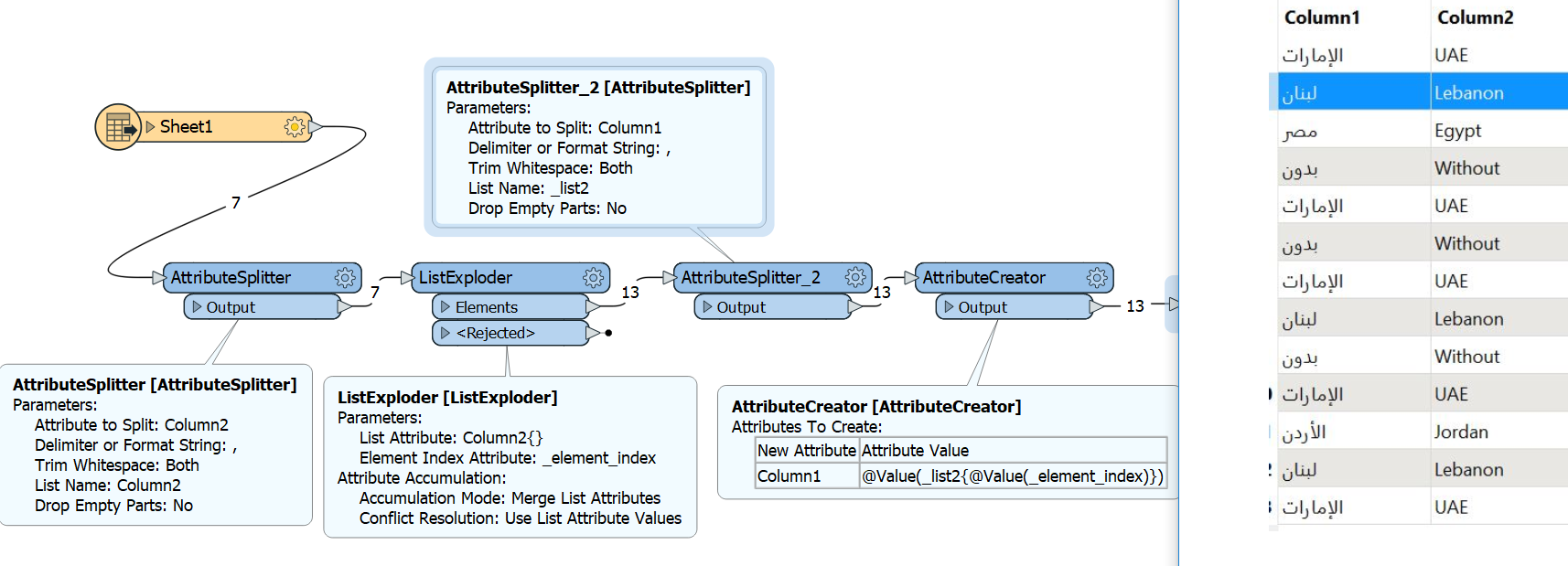
The attribute splitter for me splits right to left with arabic characters
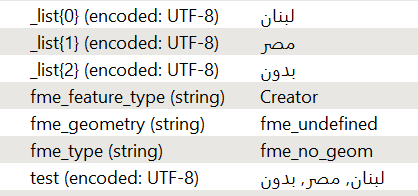
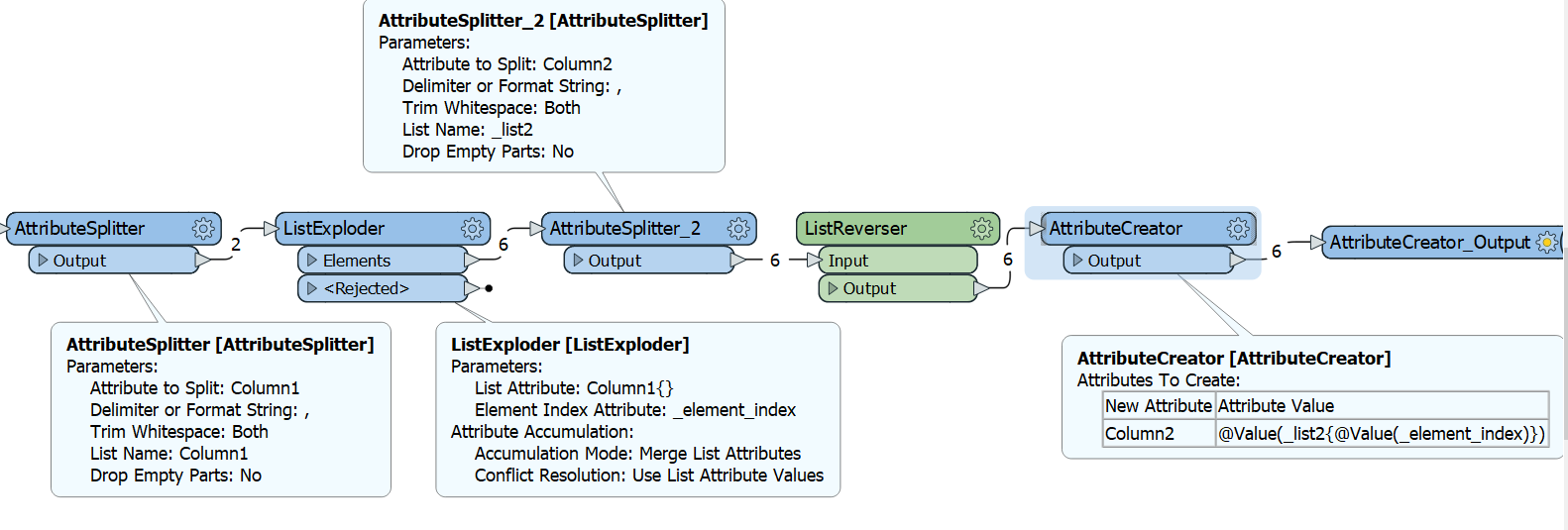
So the following process should work
Use two attribute splitters, to split both columns, make sure to give the lists different names. Explode one of the lists, and then use the attribute element index in an attribute creator to access the correct list element for the other column
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.