


I'm trying to work out how to parse the SAMPLES attribute from the Trace component of the SEG-Y reader. The reader outputs the samples as encoded FME Binary which is represented as HEX in the attribute viewer. 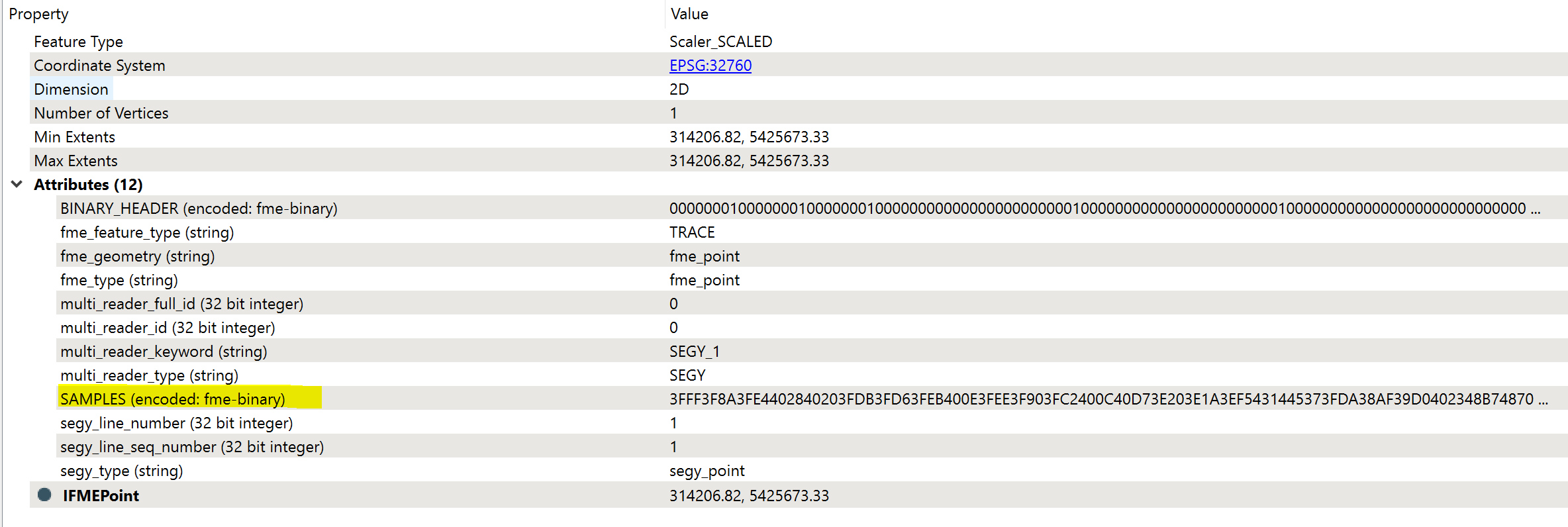 The samples are a byte array of 246 consecutive UINT16 readings
The samples are a byte array of 246 consecutive UINT16 readings
I want to parse the samples into a list of UNIT16 values so I can then do some analysis on them.
I have tried a whole range of approaches to process the string into a list of numbers but nothing seems to work and I suspect I'm just missing something.
Anyone have any ideas?
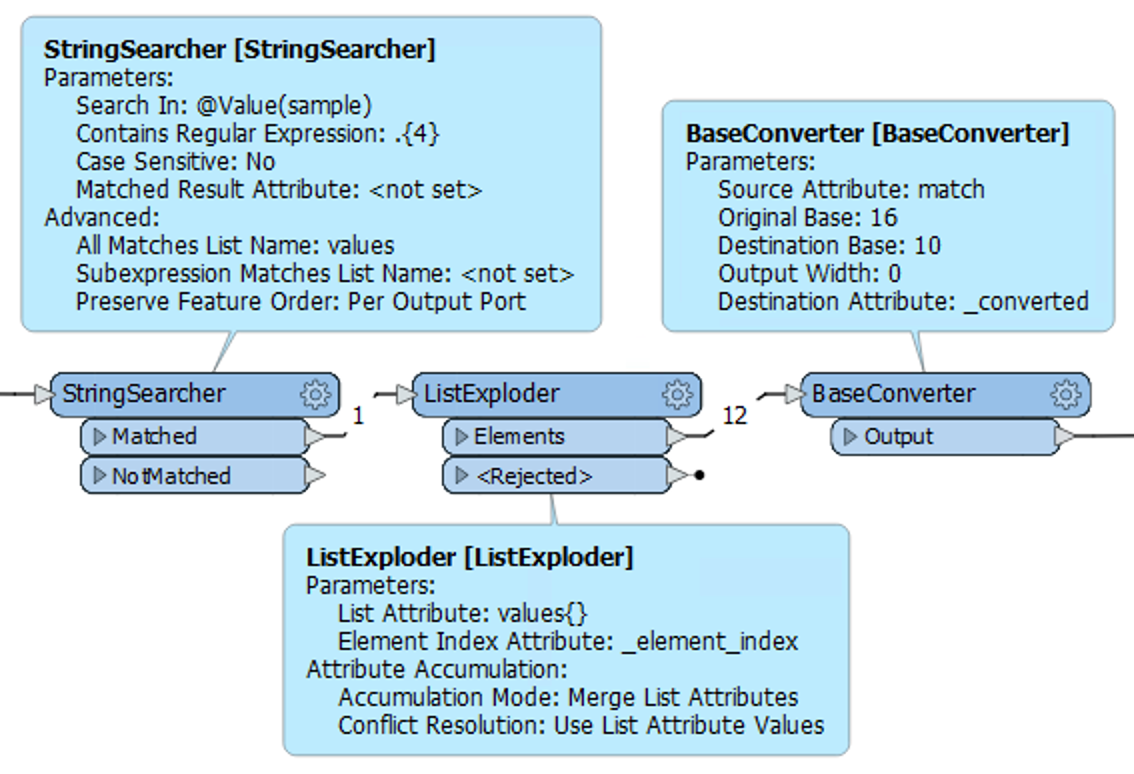





")