

Hello friends, @takashi @imj @egomm @gio @david_r
I have an attribute filled with river names, but some are abbreviated and i need to write out them.
eg:
- Rch. das Pedras Negras >> Riacho das Pedras Negras
- Rib. da Saudade >> Ribeirão da Saudade
- Córr. da Cachoeira >> Córrego da Cachoeira
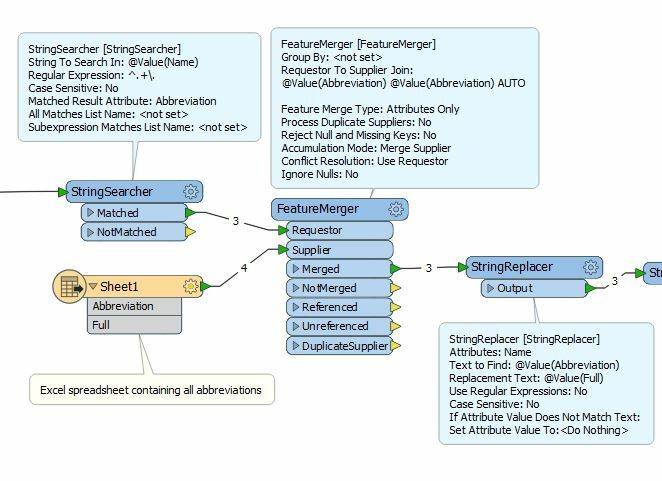
I use StringReplacer to match each short text, but, in this way, i've to put one StringReplacer for each short text. I saw in forum some topics about regular expressions (i don't have expertise in RegEx,so i've to begin studying it) with StringReplacer and i figure out to use only one StringReplacer to replace all of short texts.
Is there a way to do this with stringreplacer using regular expressions? I do some tests using this parameters:
- Attributes: text_line_data
- Text to find: (^Córr.)|(^Rib.)|(^Rb.)|(^Rch.)|(^Cach.)
- Replacement Text:
- Use Regular Expressions: yes
- CaseSensitive: no
With this parameters i can isolate the short texts, but now i need a regular expression that replace the short texts for full texts.
Thanks for all!!



")




