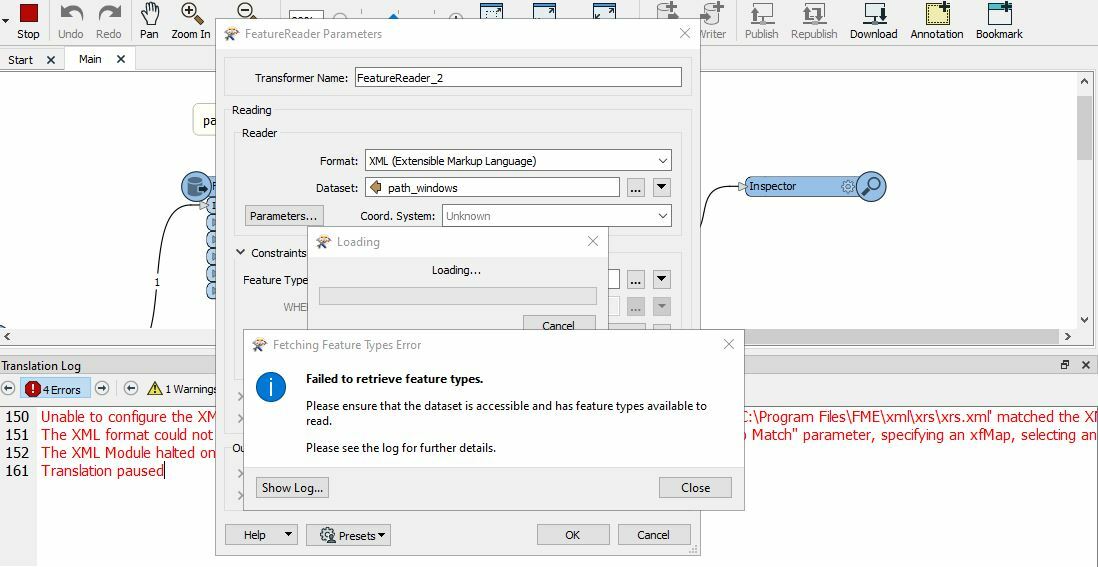
Okay, hence it is not possible to read XML in the middle of a workflow ?
I set my FeatureReaders to SingleOutput port but that does not make a difference.
It depends 😃 If your schema is fixed, it is perfectly doable:
- In the FeatureReader XML reader, select a sample file in Dataset.
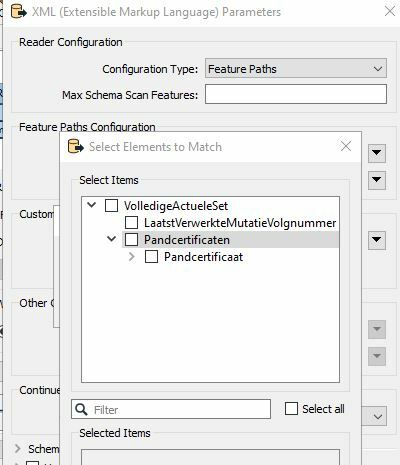
- In the Parameters, select the elements to match. (Assuming you use Feature Paths.)
- Set Output Ports to Single Output Port. *
- Test if this works as expected.
- Now change FeatureReader XML reader Dataset to path_windows.
* You can choose to set Output Ports to One per Feature Type, but then you need to select the sample file every single time you make a change to the FeatureReader, to populate the outputports. And that quickly becomes annoying in my book.
Another way of dynamically processing XML is to use a Text Reader (Read Whole File at Once = Yes) and process the attribute with the XML using XMLFragmenters.