Hello,
I'm currently having a problem with my PostgreSQL and Postgis writers.
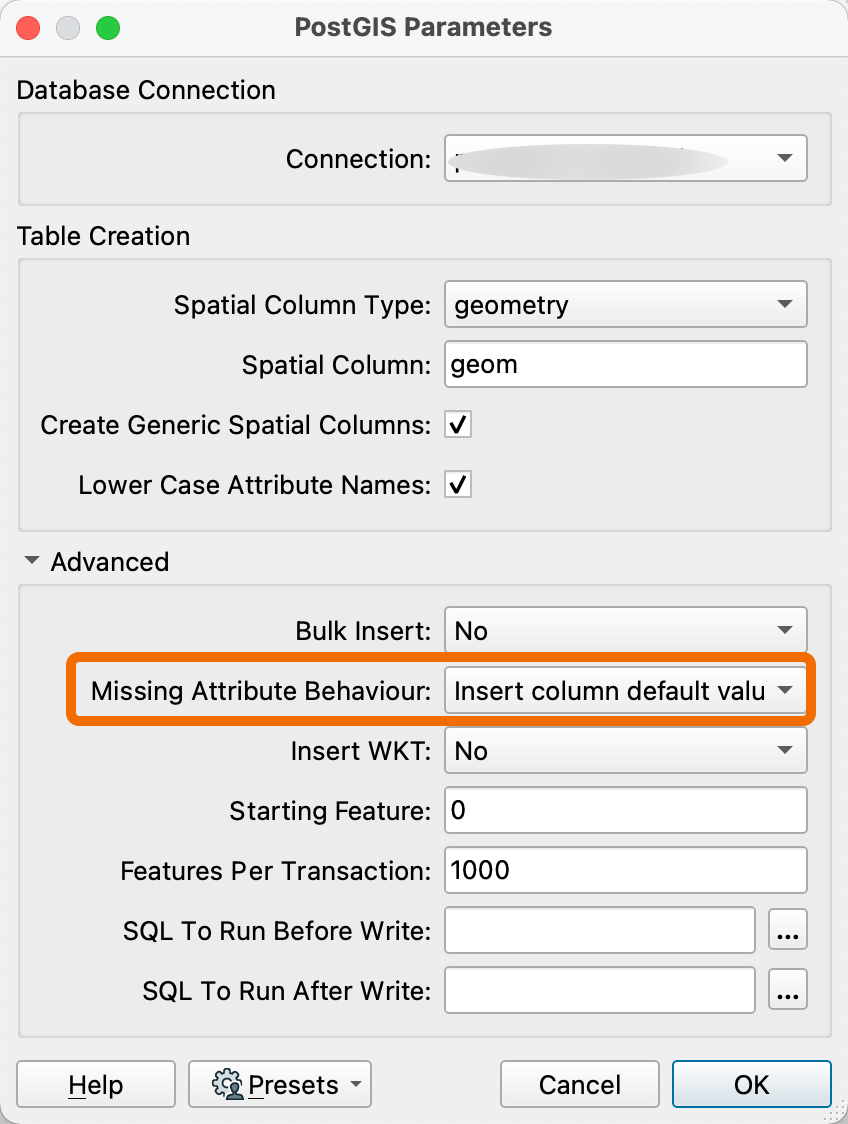
When the feature operation is set to "INSERT", the INSERT is perform on all columns of the table instead of just the columns that are specified in the attribute definition.
It result in empty data on columns that arn't defined in the feature attributes but have a default value in the DB.
For exemple :
I have a table with 4 columns (column_1, column_2, column_3, column_4).
The column_3 have a default value ('my_default')
In my script, I have a feature to INSERT some data into this table. This feature have an automatic attribute definition (to avoid defining every new column each time I modify my script).
But my customer havn't any data for the column_3 and the column_4.
So, the feature in FME have only column_1 and column_2 defined in it's attribute definition (beacause I chose the automatic definition option).
After I run the script, the result I'm expecting is this one :
column_1column_2column_3column_4data1.1data1.2my_defaultNULL
Instead of this, I have this result :
column_1column_2column_3column_4data1.1data1.2NULLNULL
It's beacause FME perform this request :
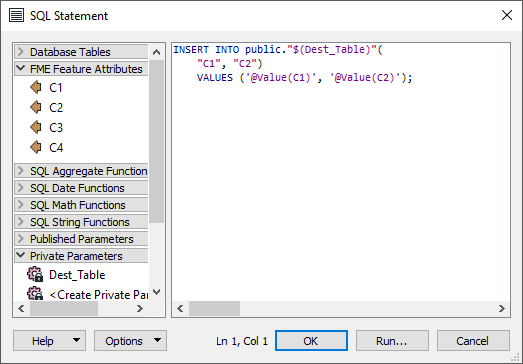
INSERT INTO my_schema.my_table (column_1, column_2, column_3, column_4)
VALUES ('data1.1', 'data1.2', NULL, NULL);Instead of this one :
INSERT INTO my_schema.my_table (column_1, column_2)
VALUES ('data1.1', 'data1.2');
As it inserts NULL value for the column_3, the default value can not be used.
My question :
Is there any option to avoid this behaviour and keep my default value ?
PS : I've extremly simplified my case, as our data model is constantly evolving, it will be complicated to define the structure of every table in the attribute definition of FME. It's easier to INSERT only in column that have data and let others working with default values.
The automatic definition helps us as we just have to name a field with the correct name to have it inserted in the DB (we don't have to defined it into the attribute definition).