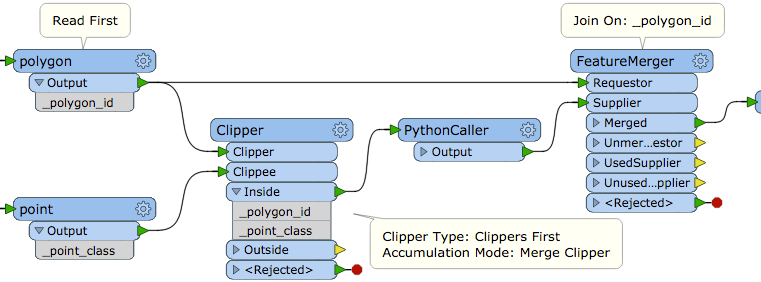
Hi I have a point and polygon layer. I need to populate different counts of points in each polygon satisfying different attribute queries on the point layer.
e.g count of supermarkets, sports centre in each polygons. I have 8 such queries, so would populate 8 fields in the polygon layer.
I tried using TestFilter on point fc then PointOnAreaOverlay, but this doesn't work as I cannot get multiple If and If statements from TestFilter. Instead It gives me If Else If.
I would like to avoid having 8 different TestFilters and PointOnAreaOverlay transformers if possible.
Any ideas?