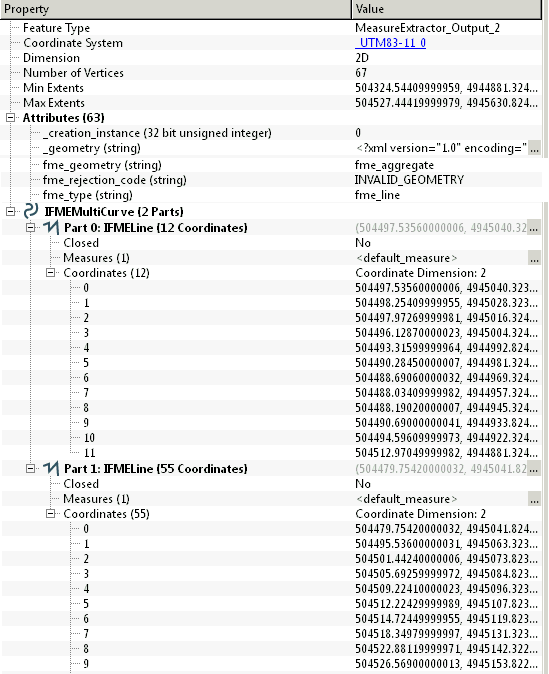
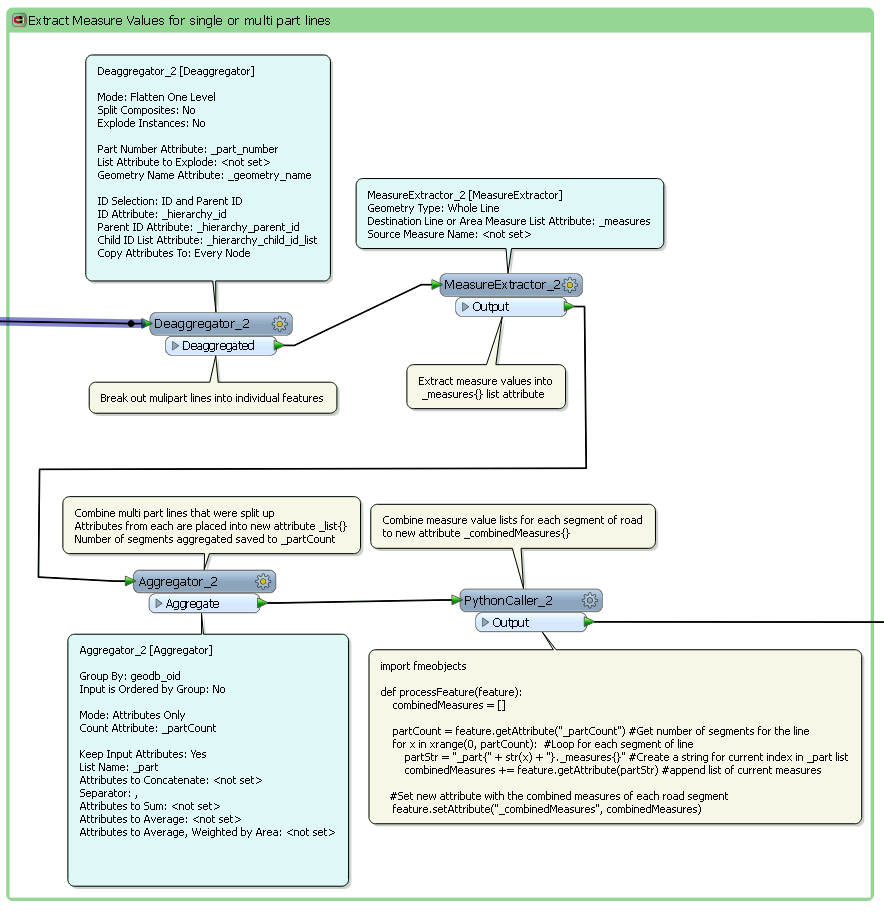
I'm working with roads data from an ArcSDE reader and trying to expose all measure values into an new attribute list using the MeasureExtractor transformer.
It's working great for roads that are continuous/have only one part [fme_geometry = fme_line]. However, when roads that have multiple parts [fme_geometry = fme_aggregate] pass through the MeasureExtractor instead of having a new _measures{} list exposed, there is only a new attribute, [fme_rejection_code = INVALID_GEOMETRY]. Can the MeasureExtractor be setup to handle these fme_aggregate features? If not, can anyone recommend an alternative workflow that would result with one feature having a single list of the combined measures for a multi part road? Thanks in advance for any insight or advice.Screenshots below of transformer settings and Inspector results. Using FME Desktop 2014.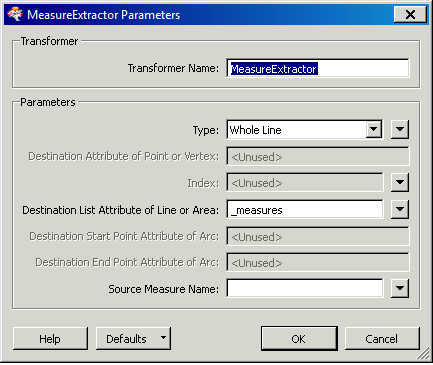
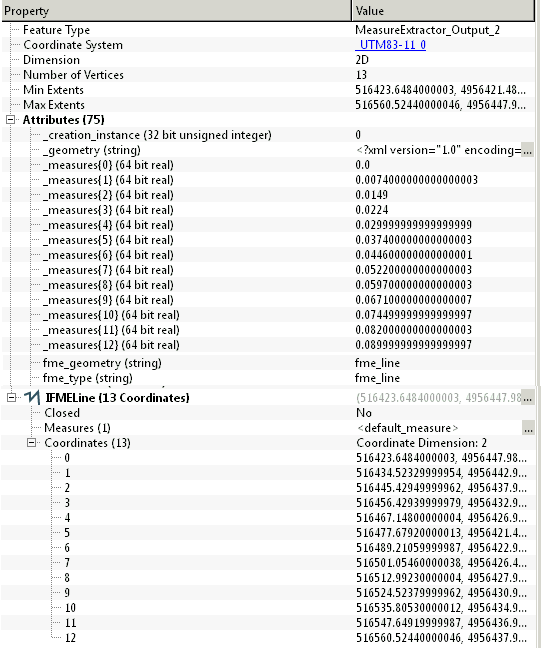
Inspector - Multi part road. No _measures{ } list created.