


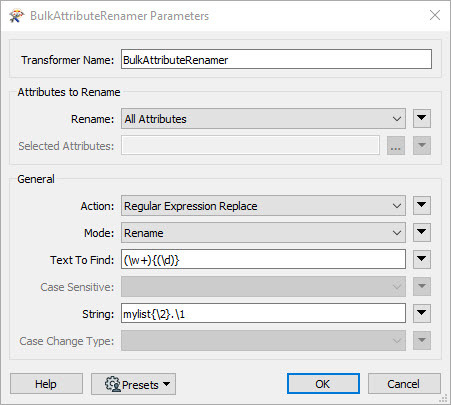
What I want to achieve is:
colour is split into list attribute colour{}
nationality is split into list attribute nationality{}
status is split into list attribute status{}
size is split into list attribute size{}
shape is split into list attribute shape{}
etc. in one go.
Thanks for you help


 I've attached an example workspace
I've attached an example workspace