


Hi, I have a file with several lines that contain information about a unique record. However only line 01 has the unique information about the property. The remainder of the lines have further information about the property and start with different numbers. The row with the main information always starts with a 01. Subsequent rows have a different number.
Can someone please advise how I would add the unique reference in the example below in the second field in line 01 (19633154000) to all the rows below until you get to the next row with line 01. Many thanks.
Eg
01*19633154000*10870539000*0335**45-47****YORK ROAD
02*1*Ground*90
02*9*First*18
04*128
01*17163059000*7648136000*6955*WILKINSON BUSINESS PARK
02*1*First*38
02*3*First*0.00
02*4*First*Kitchen*1
05*10*0**0*+0



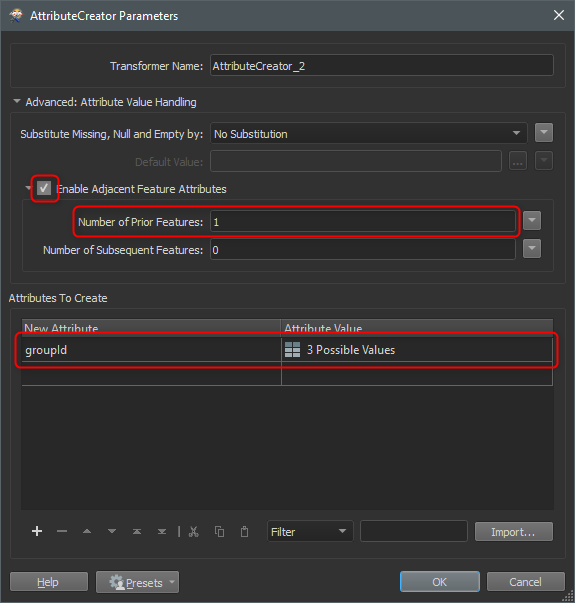 If previous row does not exist, groupId = 1.
If previous row does not exist, groupId = 1.

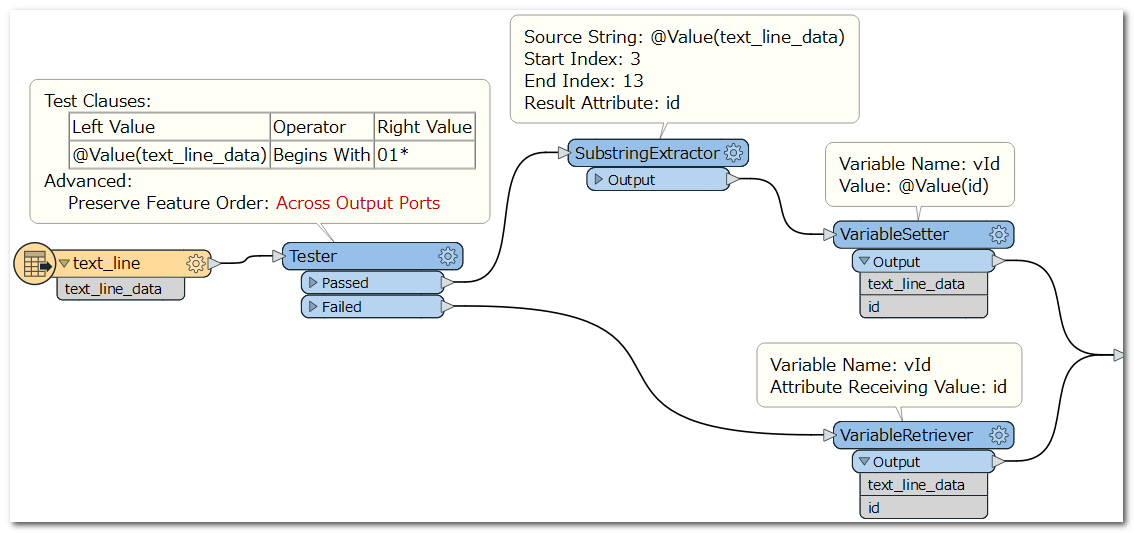
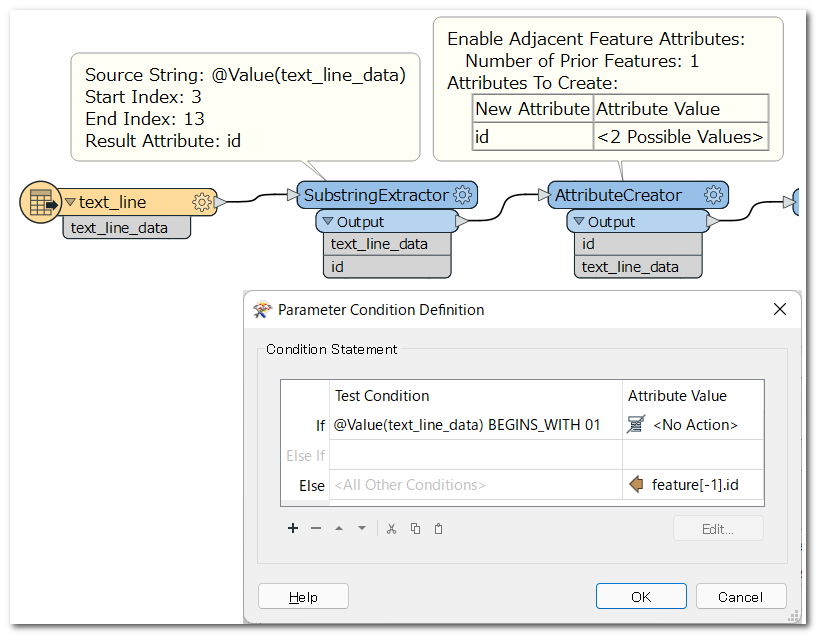
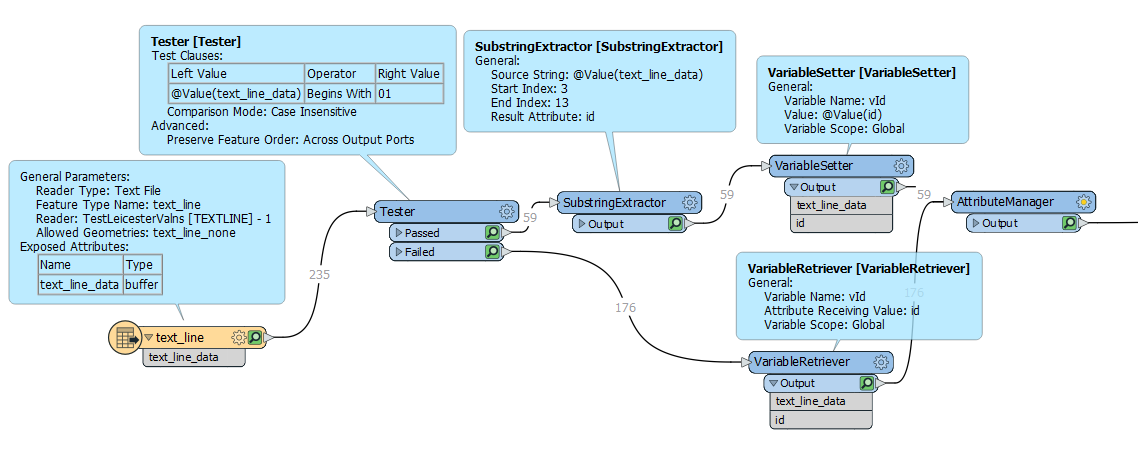
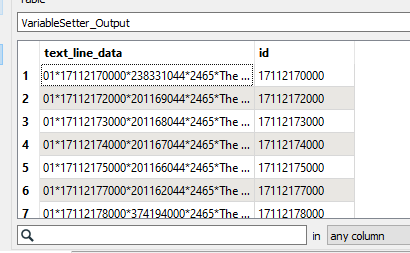
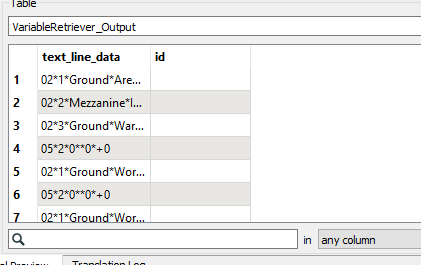
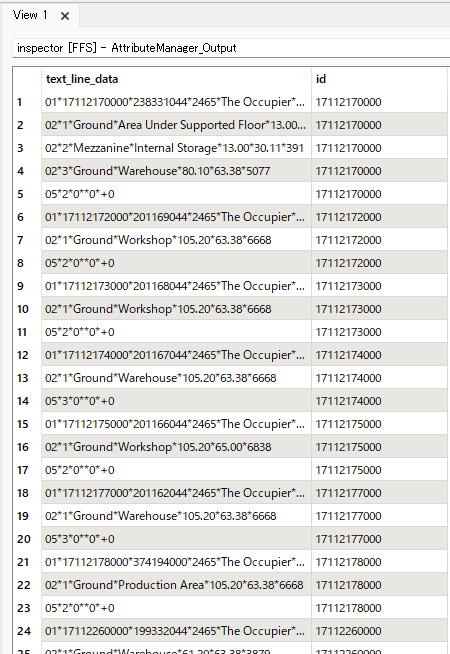



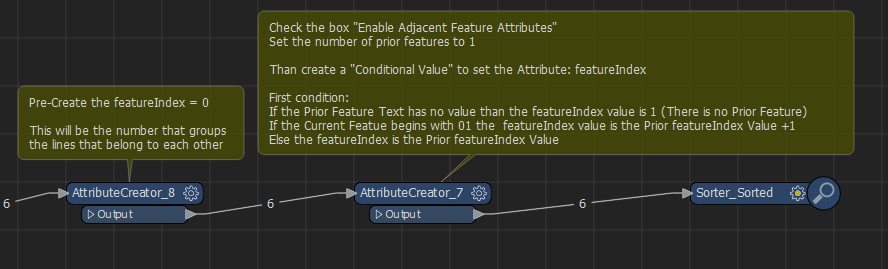 Then look at the start of your line. If it starts with the indicator for "New Feature", which is 01 in your case. Add +1 to the 'group' number of the Prior Feature for the current feature. Else use the 'group' number for the current feature.
Then look at the start of your line. If it starts with the indicator for "New Feature", which is 01 in your case. Add +1 to the 'group' number of the Prior Feature for the current feature. Else use the 'group' number for the current feature.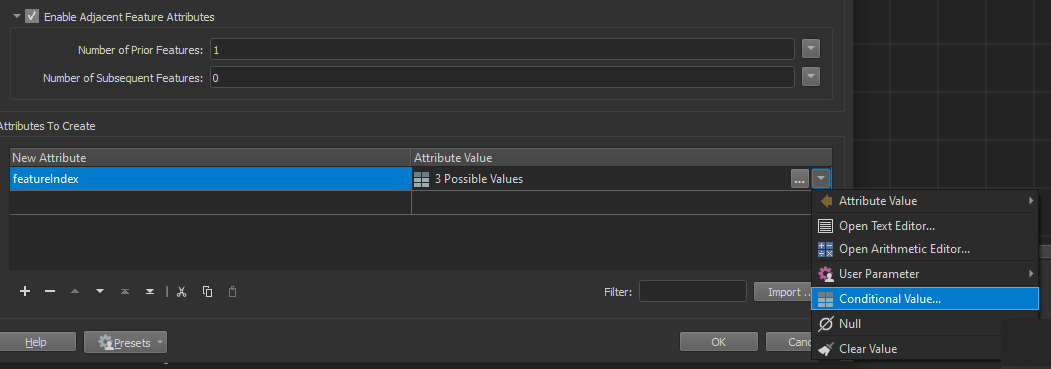 The conditional Settings:
The conditional Settings: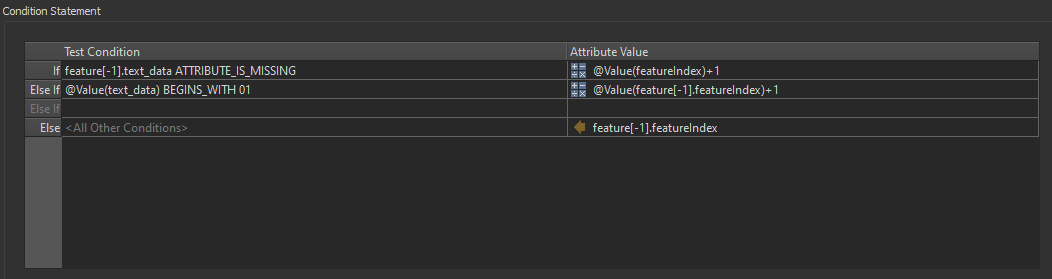 The @Value(feature[-1].featureIndex) is only available with the checkbox checked.
The @Value(feature[-1].featureIndex) is only available with the checkbox checked.