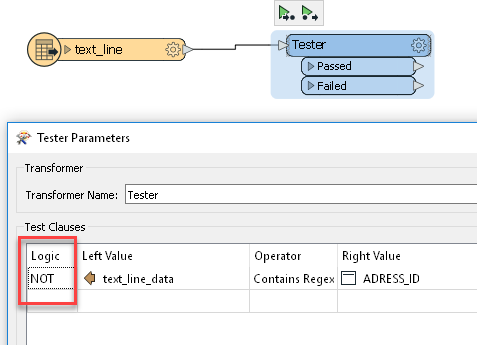
How do I remove/filter out the column that says "ADRESS_ID"/ETC?
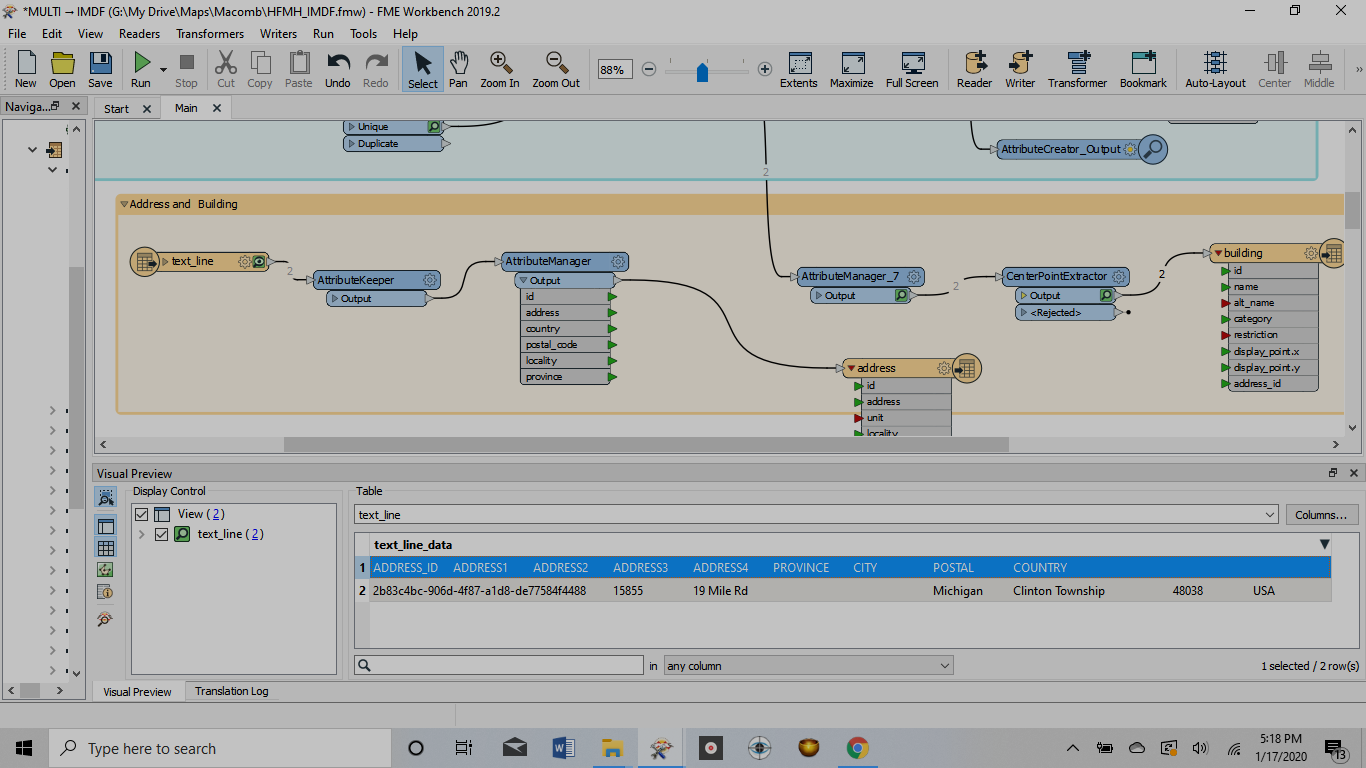

How do I remove/filter out the column that says "ADRESS_ID"/ETC?
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.