Dear all,
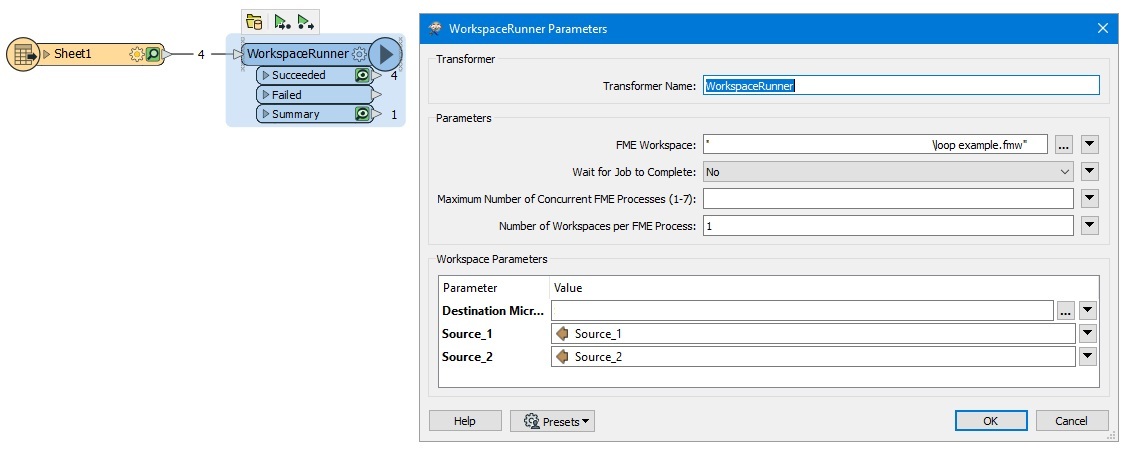
I use FME to perform a complex comparison analysis between two large datasets. I am looking for a way to analyze various subpopulations in succession, in order to reduce memory usage and increase performance. I have defined the desired subpopulations in a Reader file, so they can feed the SQLExecutor transformers to obtain the subsets. After performing the analysis on the first subset (i.e. 'Apple') and writing the results to a report file, the next subset (i.e. 'Banana') should be analyzed and so on.
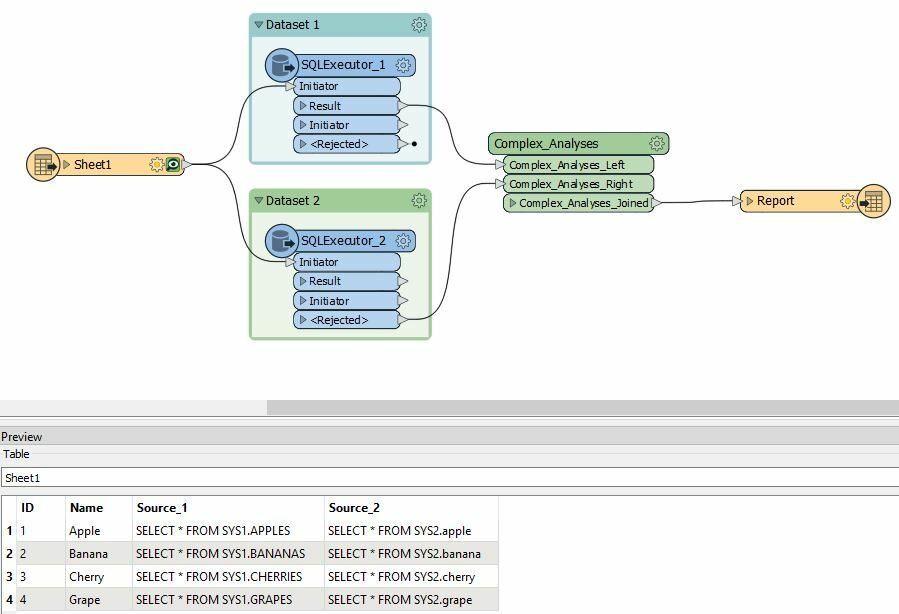
How can I implement such a 'for each loop' within FME?
Thanks in advance.
Remy






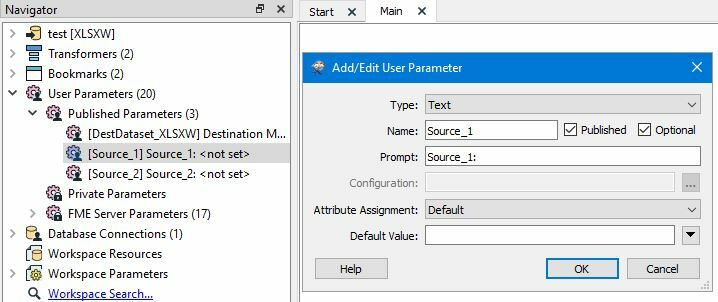
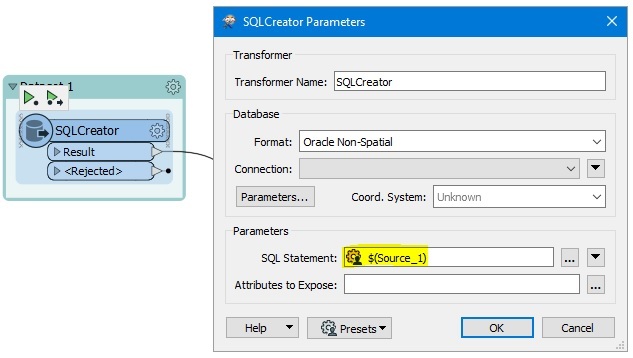 At last, I created a parent workspace that affects the published parameters.
At last, I created a parent workspace that affects the published parameters.