Hi,
I have a dataset with an attribute containing a JSON file for every feature. The dataset also has an attribute called frequency. I'd like to add the key frequency to the JSON file, with the value in the frequency attribute. I tried using the JSONUpdater transformer:
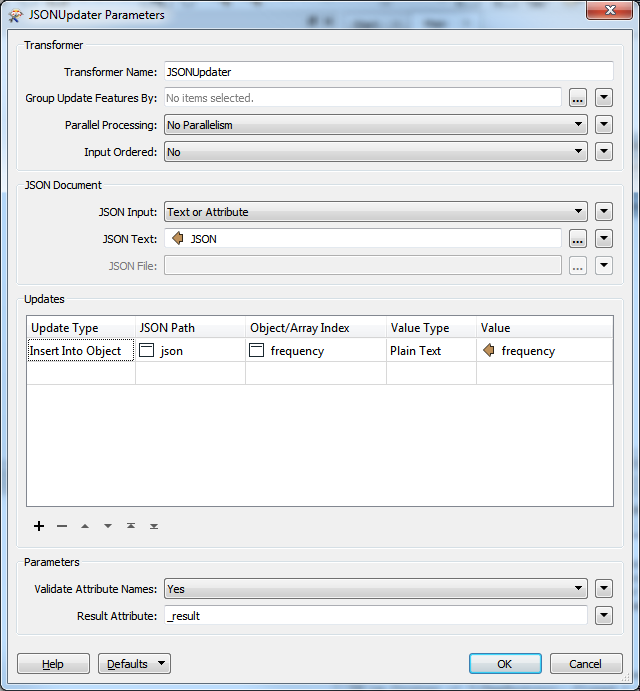
Update Type: Insert into Object
JSON path: json
Object/Array index: frequency
Value Type: Plain Text
Value: [the value of the frequency attribute]
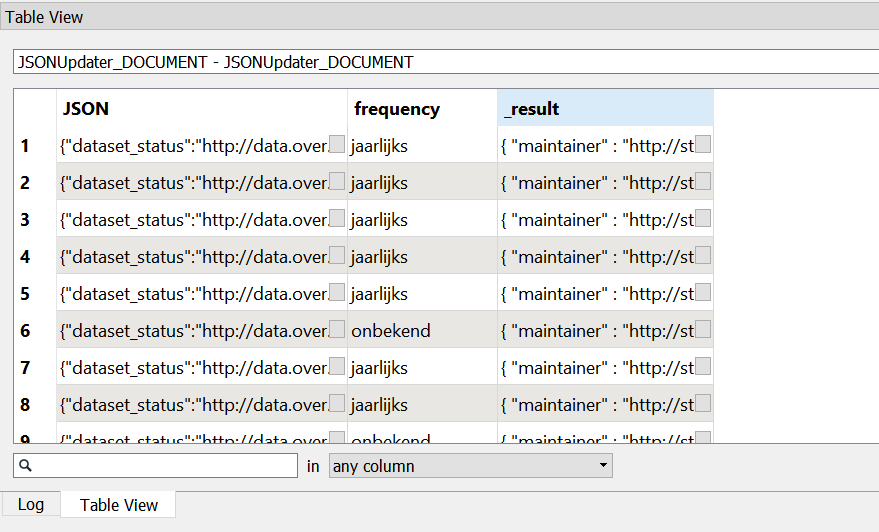
The resulting JSON file has a key frequency with a string of length 0 as a value.
I also tried:
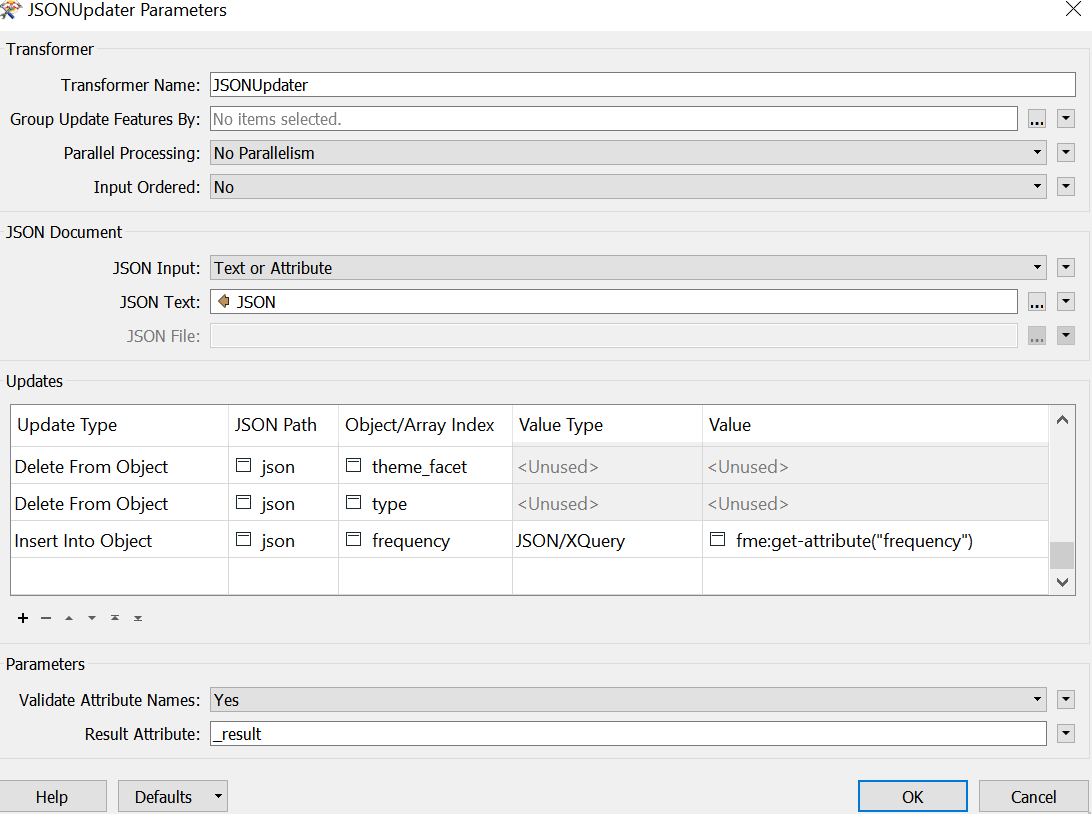
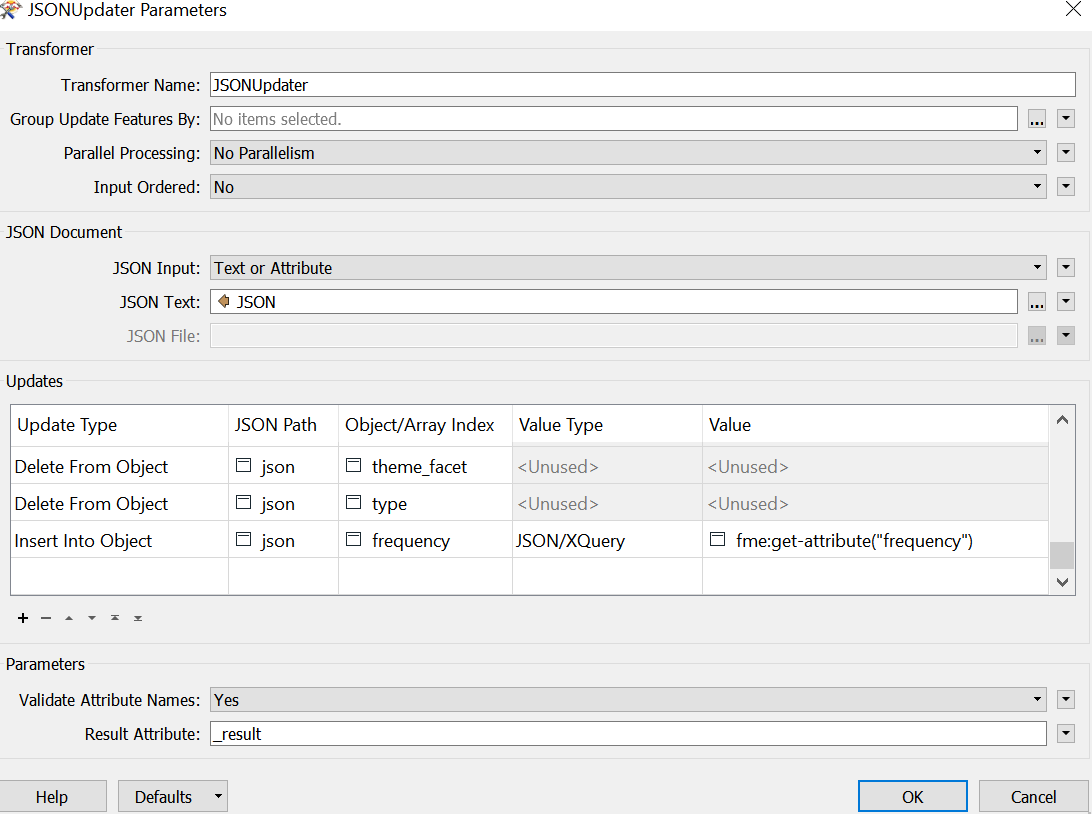
Update Type: Insert into Object
JSON path: json
Object/Array index: frequency
Value Type: JSON/XQuery
Value: fme:get-attribute("frequency")
This time the result was a key frequency with a value of null.
How do I resolve this?