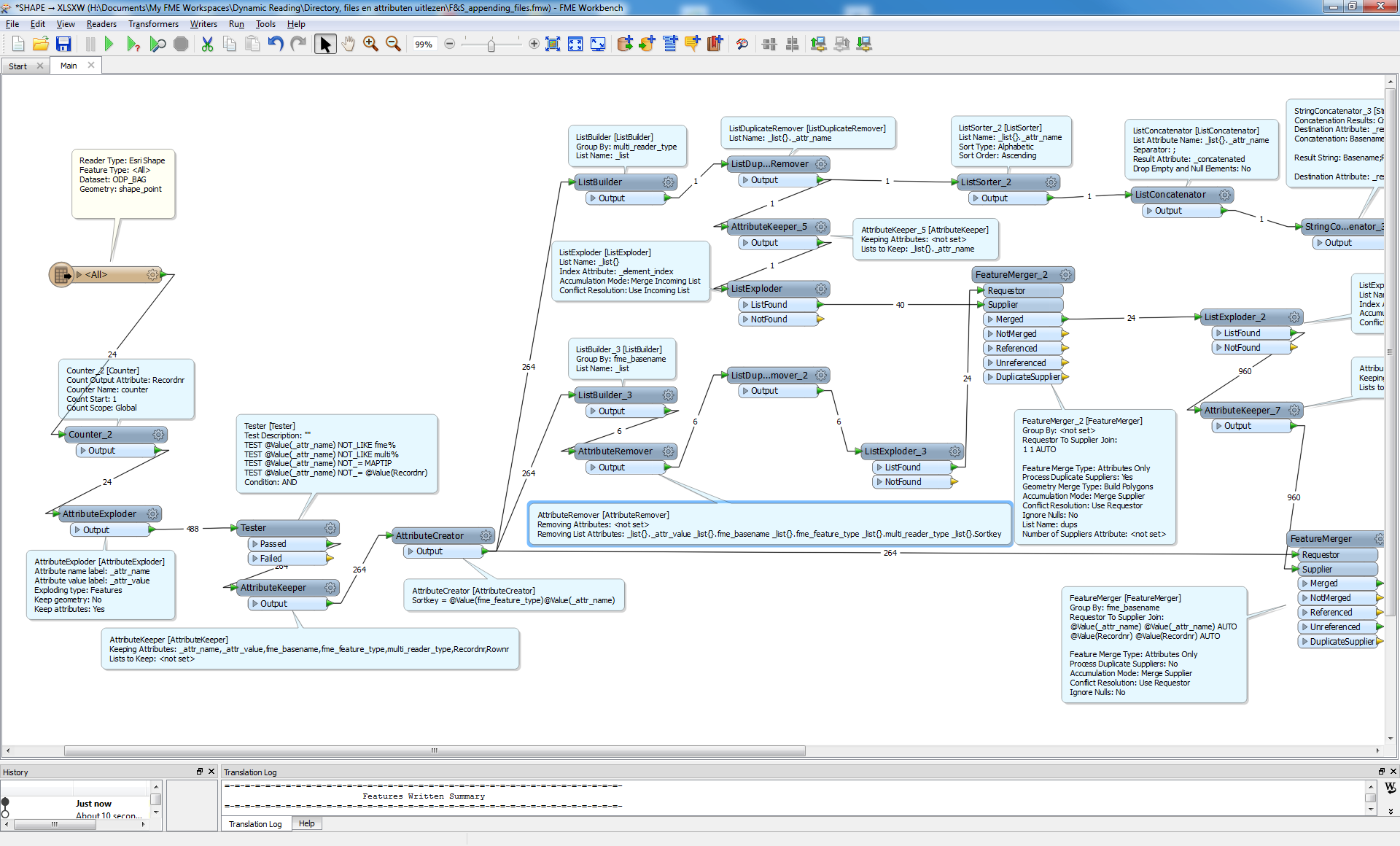
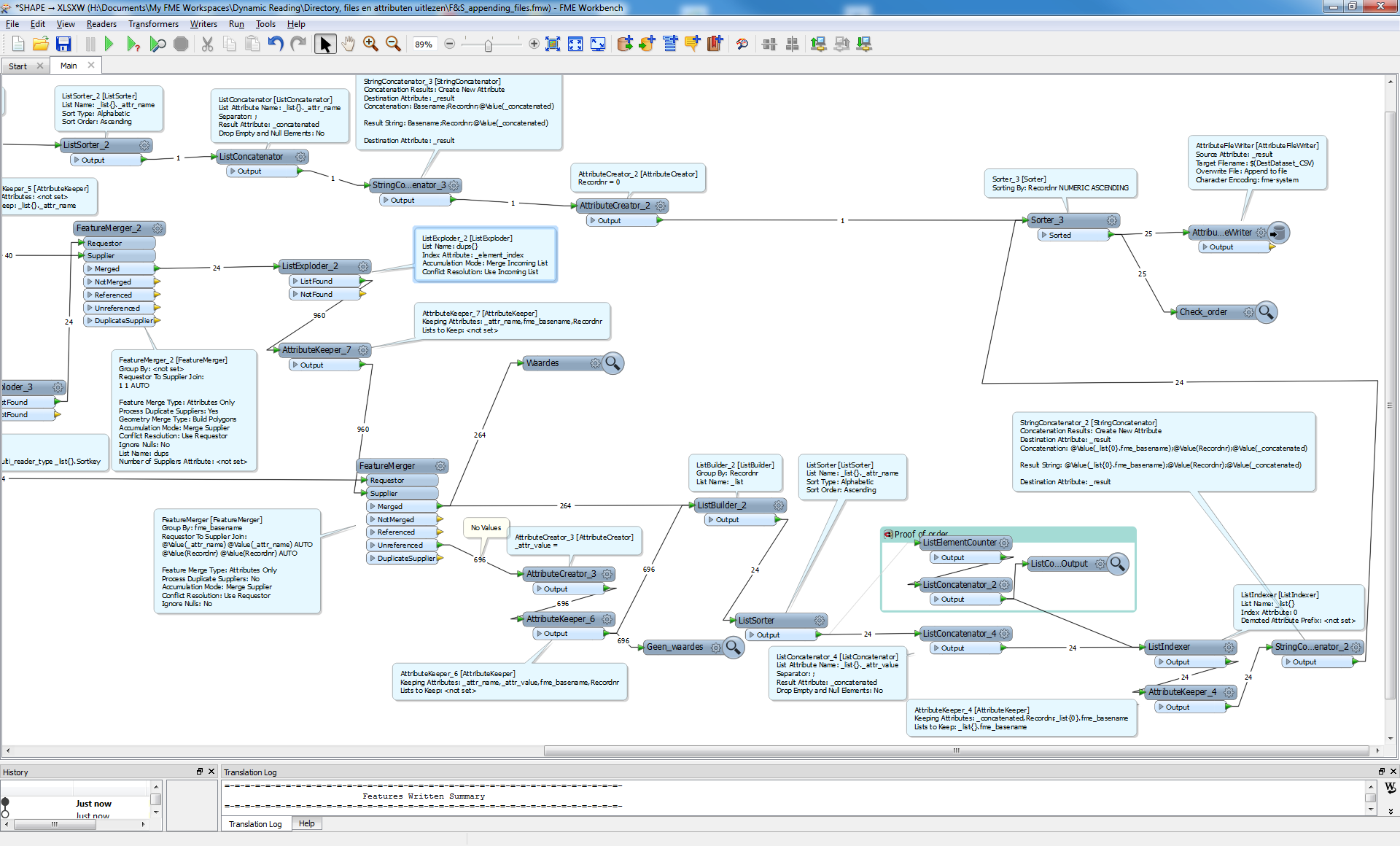
I am trying to append 5 csv files together. I also have to order their position in the final file based upon a name of an attribute in each file. As an example csv file file01.csv has a field called abcd, file02.csv has a field called abcde and file03.csv has a field called abcdef. I want to merge all the csv files together so that the contents of file01.csv appears in lines 0-10, file02.csv in line 11-20 and file03.csv in 21-30.
The merging of the files can be achieved by using the string concatenator and then writing only the _concatenated field to another csv file. But what I cannot do is order the position in which the files are writen into the final csv file. Due to the contents of the csv files, after the string_concatenator runs, all the fields are written into a single attribute. The name of the attribute is the summation of all the fields in the original file. The files which should appear at the top of the final csv file also have the shortest attribute name. Therefore I am thinking that if I could access the attribute name and use the length of the string as the import-criteria for the import, the shortest would be at the top and the longest at the bottom. Therefore I am asking the question, how can I expose the name of an attribute an use it for further processing.