
I am trying to extract text from a data catalog website to use for metadata updating. I think I have all the pieces to get a line of text with the correct CSS selector. The problem is that the HTTPCaller doesn't even seem to register anything after the <header> tag so I can't extract anything in the main body. My output always comes out null.
Here are a few screenshots of trying to just extract the title of the dataset page:
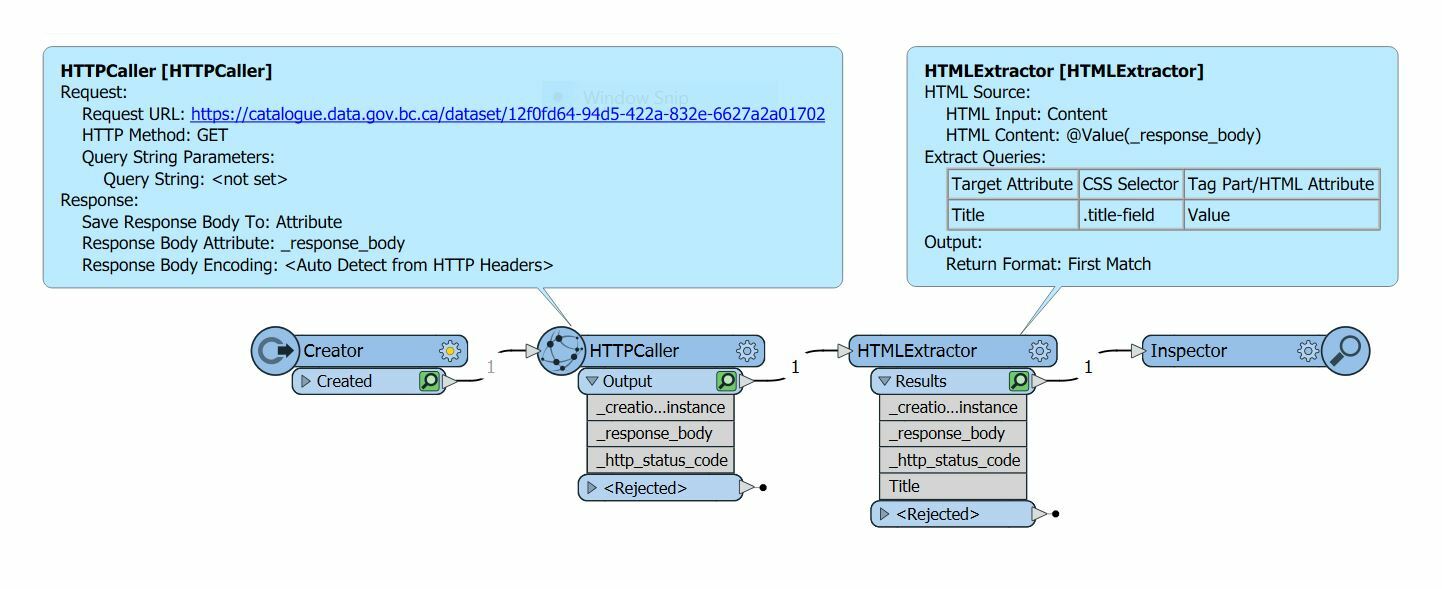
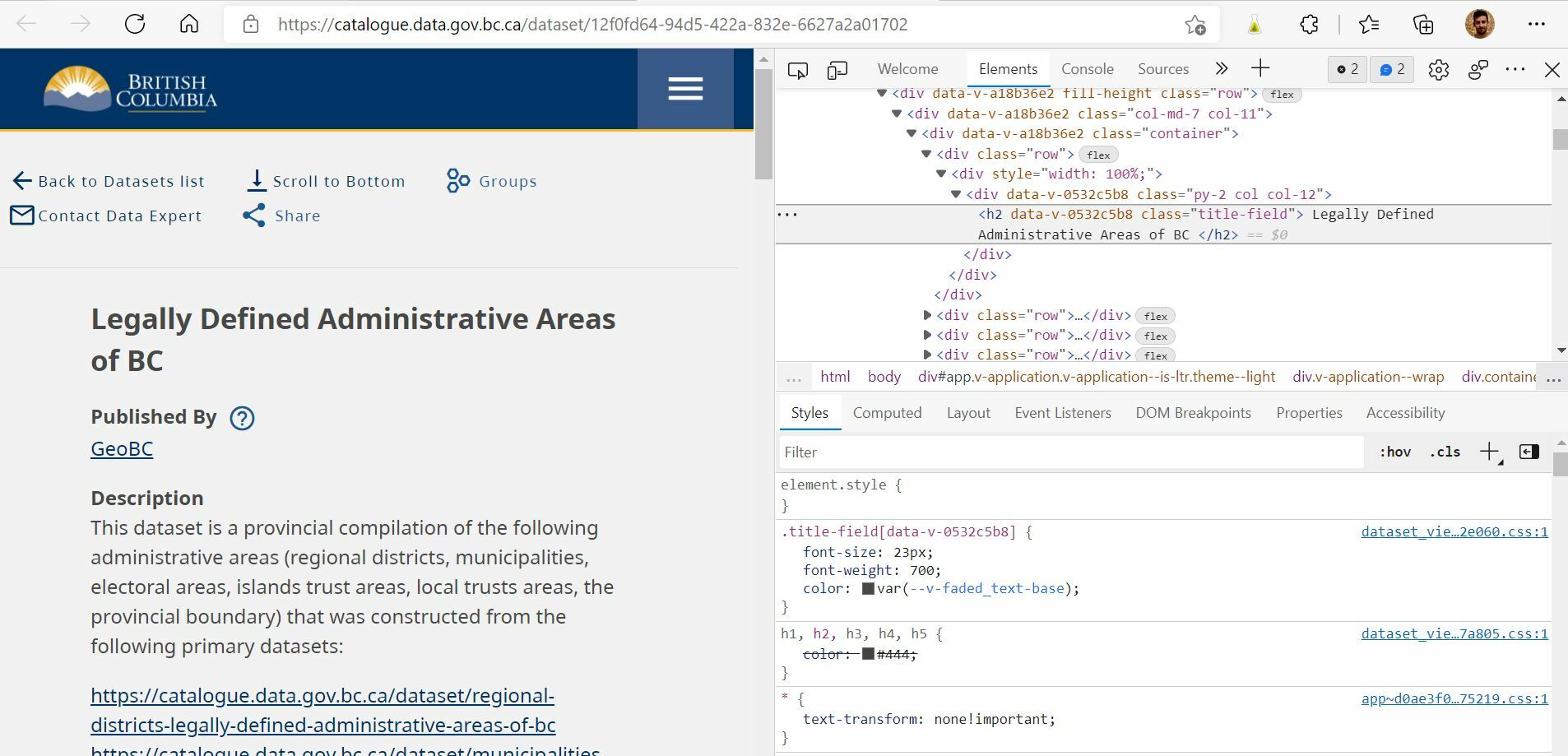
 The _response_body returned from the HTTPCaller doesn't even have the main <body> section.
The _response_body returned from the HTTPCaller doesn't even have the main <body> section.
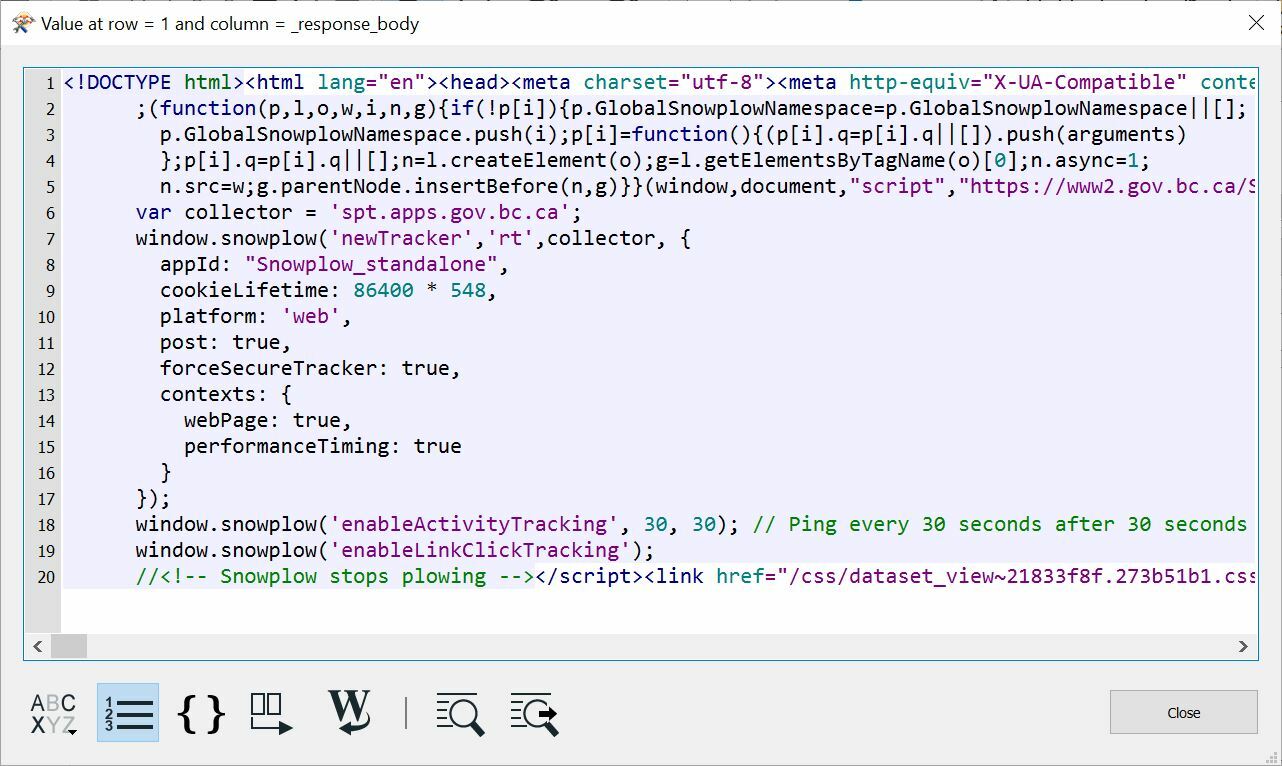 Is there any way to force the HTTPCaller to recognize anything past the header tag or is this a security feature of the government website?
Is there any way to force the HTTPCaller to recognize anything past the header tag or is this a security feature of the government website?
Thank you for your help!

