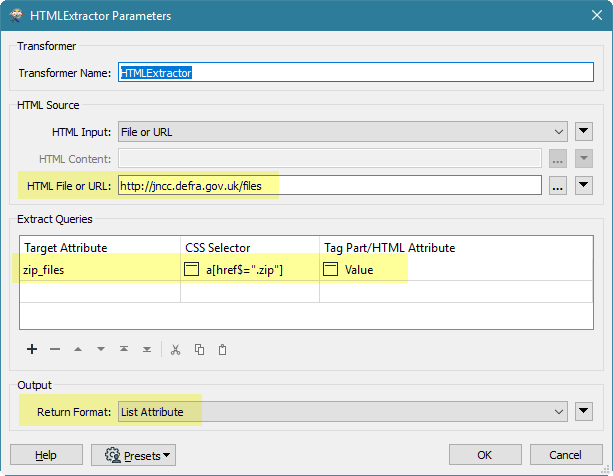
I'm trying to automate my downloads of government environmental data. Unfortunately the zipped shapefiles change name because they put the date in the file name. I've found that they all end up in this location though: http://jncc.defra.gov.uk/files
So my current thinking is to get FME read this page and filter on the zip file name, then use httpcaller to download the right zip. When I go to this page in my we browser it displays a bit like a table - is there a way to get FME to read it as a table?