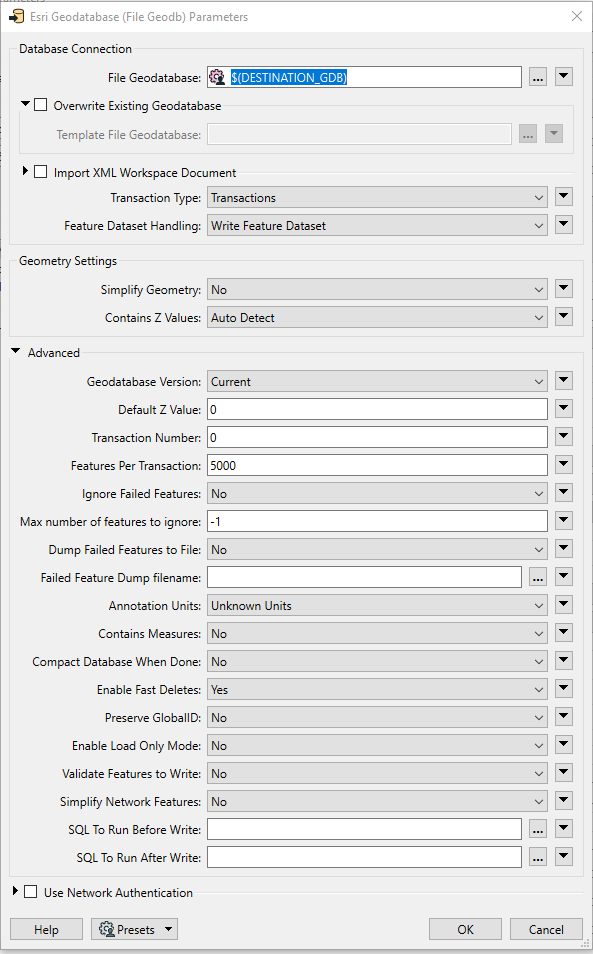
Hi All,
Today’s million dollar question: I have created a workflow to process some polygon and table data into a template GDB. The process isn’t too complicated but I think the most consuming transformers in the process are the DataTimeConverter and the FeatureWriter. I have done some tests but assume that processing around 94M of records will takes days.
Mainly, writing 94M of records into a gdb template will be a nightmare.
Here is a screenshot of the workflow, I have also attached a version of it:
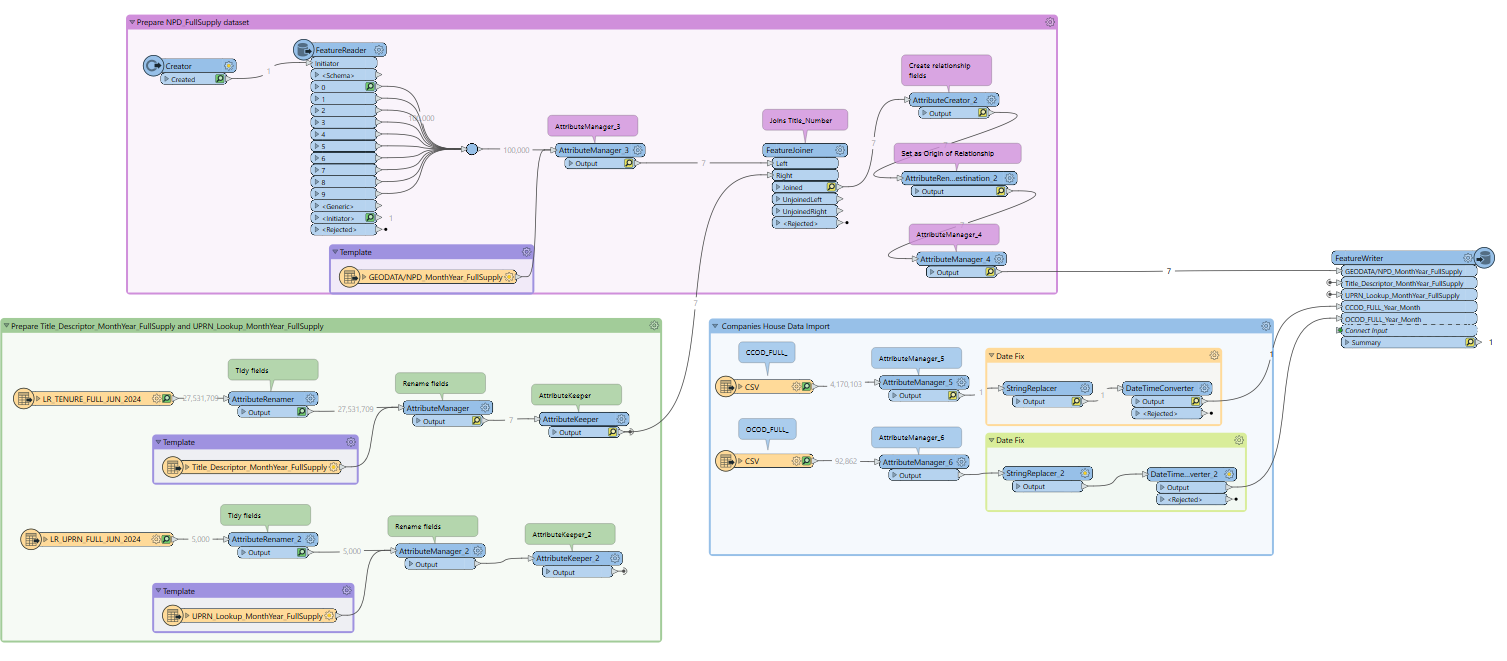
How can I improve the performance of the workflow and process around 94M of records in a clever way?
Open to suggestions :)
Thanks