Hello there
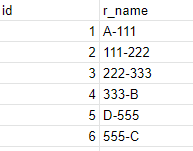
the data we have looked like this as a sample
 as you can see each end value of the r-name is the start of the next feature
as you can see each end value of the r-name is the start of the next feature
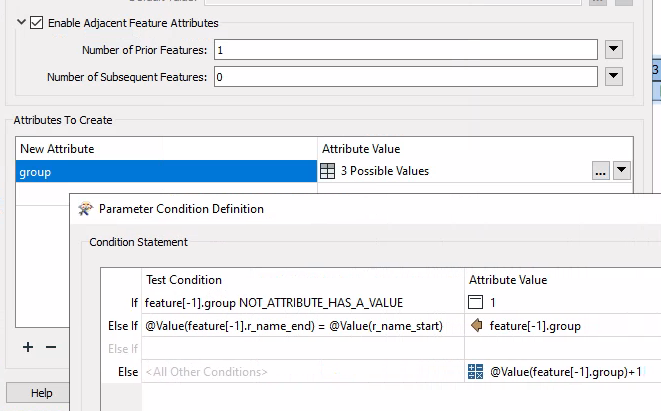
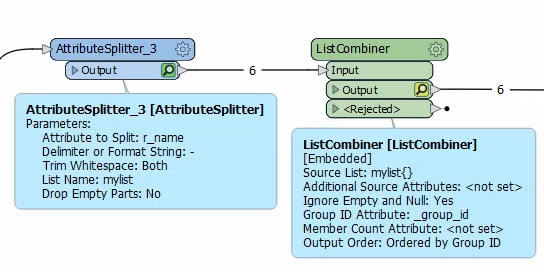
the goal is to group them based on this relationship
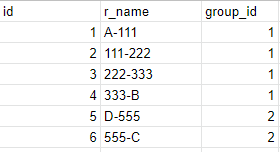
end result should look
 Thanks
Thanks

 +11
+11Hello there
the data we have looked like this as a sample
as you can see each end value of the r-name is the start of the next feature
the goal is to group them based on this relationship
end result should look
Thanks
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.