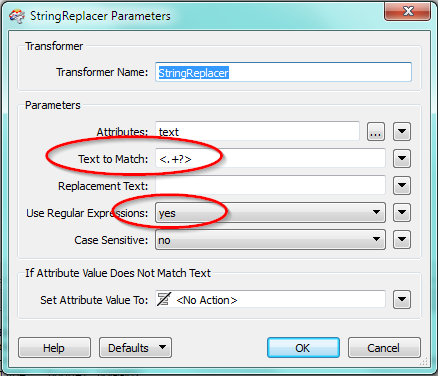
")
I need to decode a clob that I read from an Oracle database. The text stored in the clob, looks like html, and that is also what our db-admin told me it should be. So I thought I could use the TextDecoder in order to decode the html to plain text. I have tried this in both my main workspace and in a simple one where I just create a feature with one attribute with one clob. Unfortunately the TextDecoder doesnt seem to do anything with my clob. The data looks the same before and after the transformer.
Is it possibly a bug in FME or is there something else I need to consider since I am dealing with a clob? Anyone have a suggestion?
Best regards
Tobias P.
Sample clob:
<body>
<h3>32594. * (T) Oslofjorden. Oslo. Sjursøya. Lysbøyer. Nye posisjoner<em> ( Light buoys. New positions).</em></h3>
<p><strong><strong>Slett</strong></strong> tidligere Efs (T) 09/441/09<br /><em>(<strong><strong>Delete</strong></strong> former Efs (T) 09/441/09)<br /></em>På grunn av utfylling i sjø på nordsiden er følgende sjømerker flyttet:<br /><em>(Due to reclamation north of Sjursøya Mole the following light buoys has been moved):<br /></em>a) Grønn lysbøye fra posisjon (1) til (2):<br /><em>(Green light buoy from position (1) to (2)): <br /></em>WGS84 DATUM<br />(1) 59° 53.223' N, 10° 44.607' E <br />(2) 59° 53.242' N, 10° 44.611' E <br />ED50 DATUM<br />(1) 59° 53.250' N, 10° 44.693' E <br />(2) 59° 53.269' N, 10° 44.697' E <br />NGO DATUM<br />(1) 59° 53.176' N, 10° 44.896' E <br />(2) 59° 53.195' N, 10° 44.900' E <br /><span style="background-color:Yellow;">b) Midlertidig utlagt gul lysbøye fra posisjon (1) til (2):<br /><em>(Temporary yellow light buoy from position (1) to (2)): <br /></em>WGS84 DATUM<br />(1) 59° 53.222' N, 10° 44.637' E <br />(2) 59° 53.246' N, 10° 44.659' E <br />ED50 DATUM<br />(1) 59° 53.249' N, 10° 44.723' E <br />(2) 59° 53.273' N, 10° 44.745' E <br />NGO DATUM<br />(1) 59° 53.175' N, 10° 44.926' E <br />(2) 59° 53.199' N, 10° 44.948' E <br />c) Midlertidig utlagt gul lysbøye fra posisjon (1) til (2):<br /><em>(Temporary yellow light buoy from position (1) to (2)): </em><br />WGS84 DATUM<br />(1) 59° 53.252' N, 10° 44.761' E <br />(2) 59° 53.252' N, 10° 44.777' E <br />ED50 DATUM<br />(1) 59° 53.279' N, 10° 44.847' E <br />(2) 59° 53.279' N, 10° 44.863' E<br />NGO DATUM<br />(1) 59° 53.205' N, 10° 45.050' E <br />(2) 59° 53.205' N, 10° 45.066' E<br /></span>Kart <em>(Charts)</em>: 4, 401, 452. (KildeID 0). (Oslo Havn KF, 1. desember 2010).<br /><br /></p>
</body>