Hello,
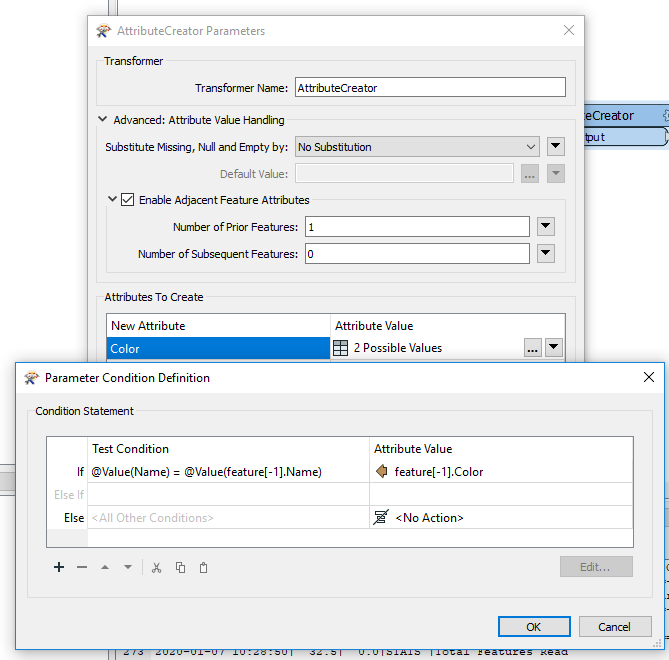
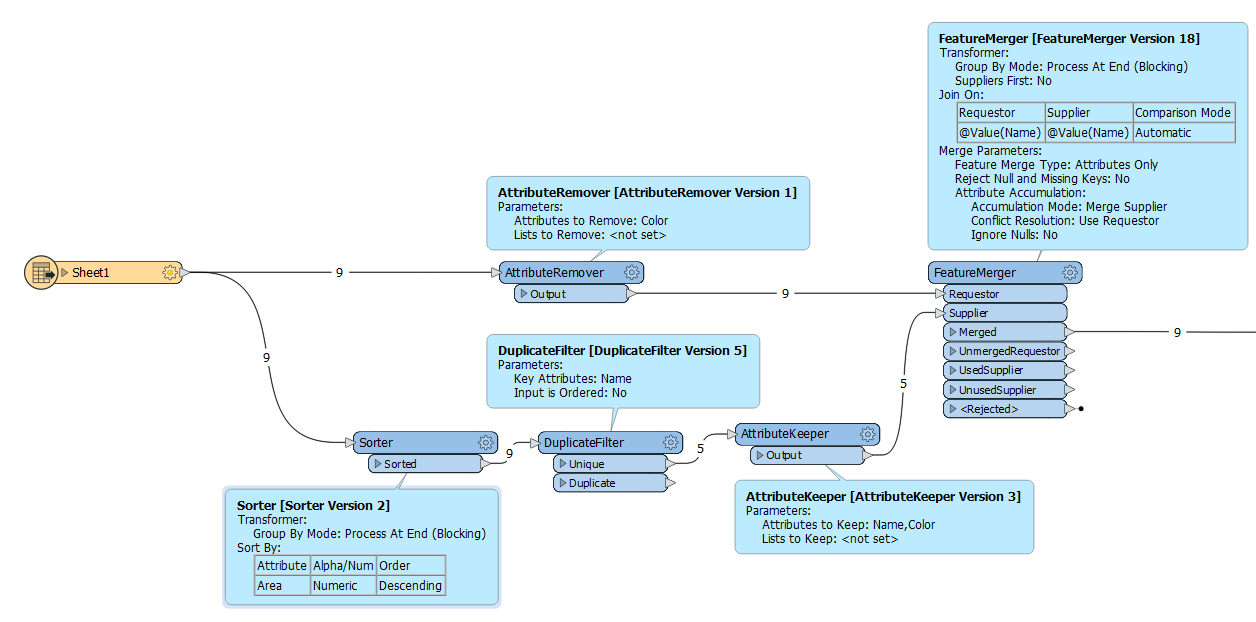
I would change the value of an attribute in a table depending on the value of other attributes group of records. Concrete example :
INPUT
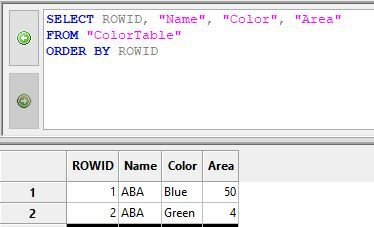
NameColorAreaAAAYellow150AZARed56BDEGreen29ABABlue298CDEGray8AZABlack76ABAOrange84BDEPurple162AZAWhite65
Sort by "Name" and "Area"
NameColorAreaAAAYellow150ABABlue298ABAOrange84AZABlack76AZAWhite65AZARed56BDEPurple162BDEGreen29CDEGray8
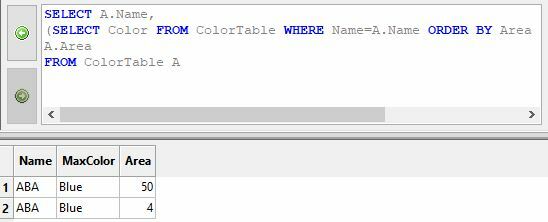
and give the same Color value as the record with the highest area
OUTPUT
NameColorAreaAAAYellow150ABABlue298ABABlue84AZABlack76AZABlack65AZABlack56BDEPurple162BDEPurple29CDEGray8
Thanks for your help.