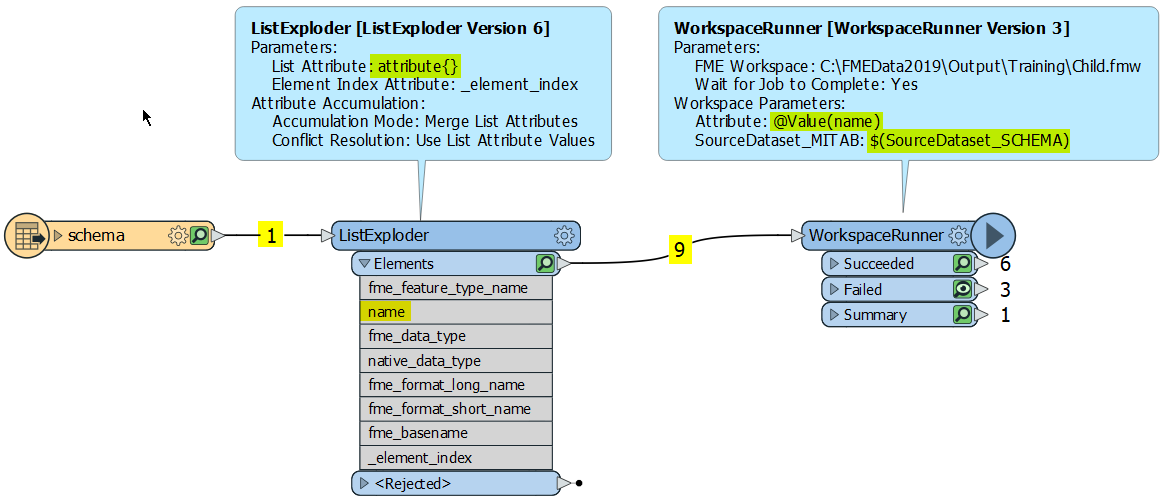
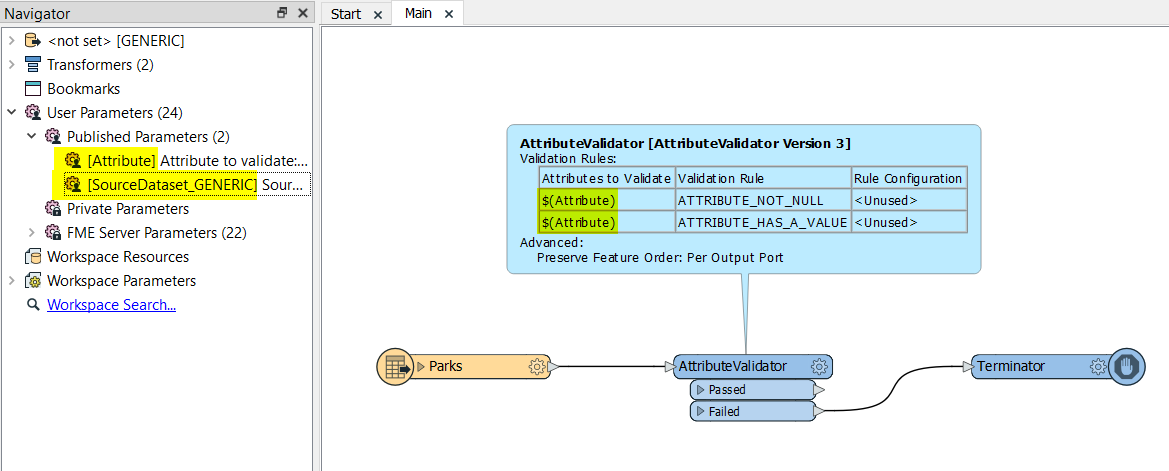
The idea is to create a generic workflow which will validate any dataset by checking all its attributes, calculating some statistics etc.
I separated it into 2 (maybe even 3 workspaces) where parent workspace reads the dataset and creates a parameters for the child workspace which is analyzing the data. The only problem is - how to set up the AttributeValidator using these parameters? I did that without any problems with the Attributes to Expose parameter of the FeatureReader (list of attribute names with space separator).
I am using 2020.1.2.0 (20200902 - Build 20620 - WIN64)