




Greetings and Happy Friday, FME Community! In today’s TGIF, Matt M joins us to discuss data lakehouses, a relatively new data solution with an adoption forecast to grow by 23% on average in the coming years [1]. What are they, and how does FME extend their capabilities?
What is a data lakehouse?
To understand what a data lakehouse is and where FME fits into the picture, we need to first understand a few key concepts.
Structured, unstructured, and semi-structured data
While these terms might be new to you, you’re most likely working with structured and unstructured data every day.
Structured data is information stored in a tabular format of rows and columns. It has a predefined format, so it’s easy and often fast to search vast amounts of data.
Unstructured data is data with no predefined format, like PDF files, images, or social media posts. While unstructured data can be rich in information, its lack of a tabular format makes it slower and more difficult to search.
Finally, there is a middle ground: semi-structured data. This is data with some structure, but it doesn’t fit into a tabular format. Examples include JSON or HTML files.
Where data has traditionally been stored
Digital storage for these types of data has existed for many decades. Relational databases have been around since the 1970s, providing organized, structured data storage that can be queried with SQL. Data warehouses expand on this by scaling up storage and management so that greater volumes of structured data from different sources can be analyzed.
Unstructured data has lived in files on various media for longer than most of us have all been alive. As storage capacities increased and costs decreased, all of this unstructured data began to be stored in large repositories, known as data lakes, so it could exist and be analyzed in one place.
But until more recently, structured and unstructured data have not been collocated. Before the somewhat recent surge of APIs, the Internet of Things (IoT), and AI, there hadn’t been as big a need.
Enter the data lakehouse
Welcome to the lakehouse. Pull up a chair on the deck, pour yourself some iced tea, and take a look at the vast landscape in front of us. The scenery is diverse because a data lakehouse combines both structured and unstructured data in one location. Now, all data is in one place where it can be discovered any analysed by all users and AI. Insights can be gained faster from varied data sources without the cost and complexity of maintaining separate data lakes and warehouses.
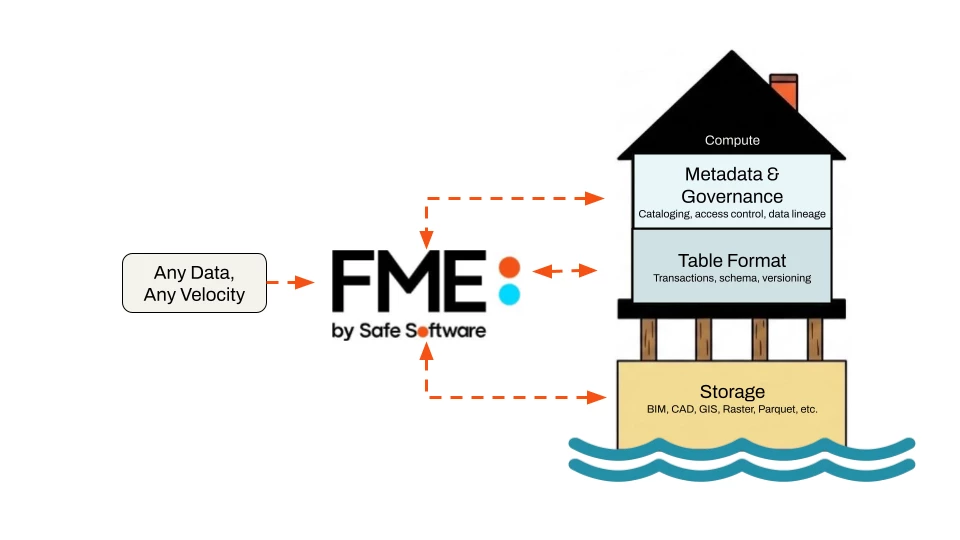
For simplicity, we’ll break things into three key layers that make this possible, but keep in mind that there is no complete architectural consensus, and different vendors draw different boundaries. We’re focusing on these three because they are the most relevant to FME.
The storage layer is where all data resides in the data lake. All data is stored in a file-based format to take advantage of relatively inexpensive storage solutions, like Amazon S3 or Azure Storage options. For structured data, the underlying file format is usually Apache Parquet. Unstructured data lives in its native file format.
The table format layer is relevant to structured data, again, usually in parquet files. This layer provides schema, transactional, and versioning capabilities on top of the raw files in the storage layer. Data can be queried with good ol’ SQL. Examples of common open-source technologies include Apache Iceberg and Delta Lake.
The metadata and governance layer brings it all together. Cataloging, access control, and data lineage are provided here. Structured and unstructured data are discoverable across the whole data lakehouse. Example technologies used in this layer include Snowflake Horizon, Databricks Unity Catalog, Apache Atlas, and Apache Ranger.
Cloud-based data lakehouses provide the functionality described above, delivered alongside processing (compute) and additional features as part of a larger data platform. Some examples include Snowflake, Databricks, Microsoft Fabric, Google BigLake, and Dremio. Cloud data lakehouses come with many features, but lack the extensive spatial format and processing offered by FME.
Extend your data lakehouse with FME
As the All-Data, Any-AI Platform, FME provides an incredibly useful extension to your chosen lakehouse technologies. FME can load and process any type of data in your data lakehouse that would not otherwise be possible without writing and maintaining code.
Use cases
Some FME use cases include, but are not limited to:
- Transform and load any type of data into your lakehouse as structured data - most lakehouses have limited support for a few key semi-structured formats like JSON and CSV.
- Interrogate your lakehouse data with any AI - you’re not limited to the AI provided with your lakehouse.
- Join unstructured, semi-structured, and structured data together to create a complete dataset for analysis.
- Perform additional validation, processing, and analysis on spatial data in the lakehouse.
- Stream data from IoT sensors into your data lakehouse using the KafkaConnector, MQTTConnector, Websockets, and more.
- For Snowflake users, perform the above using FME’s engine directly inside Snowflake, putting the processing beside your data for improved performance and security.
Lakehouse Table Formats
FME can read and write the Lakehouse table formats below
- Snowflake Reader/Writer
- Microsoft Fabric Data Warehouse Reader/Writer
- Databricks Reader/Writer
- Delta Lake Reader
- And more on the way in the near future…
Of course, FME can read and write pretty much any other type of data, including Apache Parquet.
Resources
Below are some additional relevant resources to learn more!
| Resource Type | Description | Link |
|---|---|---|
| Blog | 5 benefits of running FME Remote Engines inside Snowflake | |
| Article | Getting Started with Databricks | |
| Article | Getting Started with AI in FME: Classifying Unstructured PDF Files | |
| Article | Getting Started with AI in FME: Extracting Insights from Unstructured Documents |
Conclusion
A data lakehouse is a collection of structured (the data warehouse) and unstructured (the data lake) data brought together in one place to help create a complete picture of your data and the stories it tells.
If you’re new to data lakehouses, I hope this helped explain the key concepts and how FME can extend them. There is a lot more to discuss, so look for future posts on specific data lakehouses. Which data lakehouse solutions are you interested in? Are you already using a data lakehouse or do you plan to? Let me know in the comments.
Thanks for reading and have a great weekend! 🏖️
[1] Grandview Research Data Lakehouse Market Report. Report Summary. Retrieved March 25, 2026.