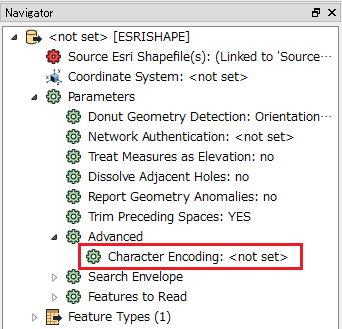
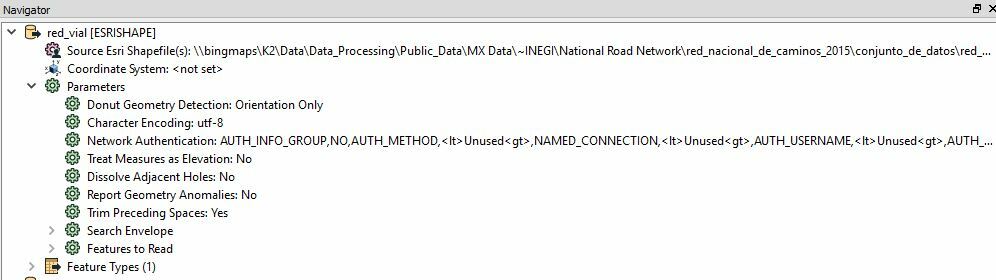
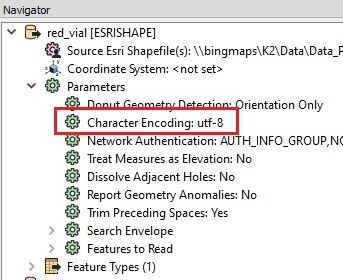
I'm attempting to perform some transformations on an ESRI shapefile in FME and am running into some issues. The attributes within the shapefile are all in Spanish. When I export back out to ESRI shapefile, it is not retaining the shapefiles' originally encoded language properties, instead inserting incorrect special characters.
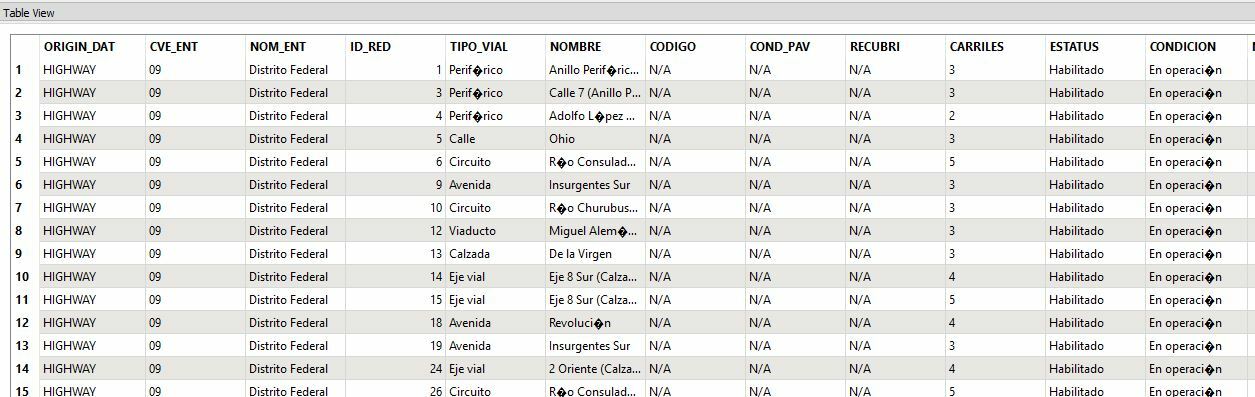
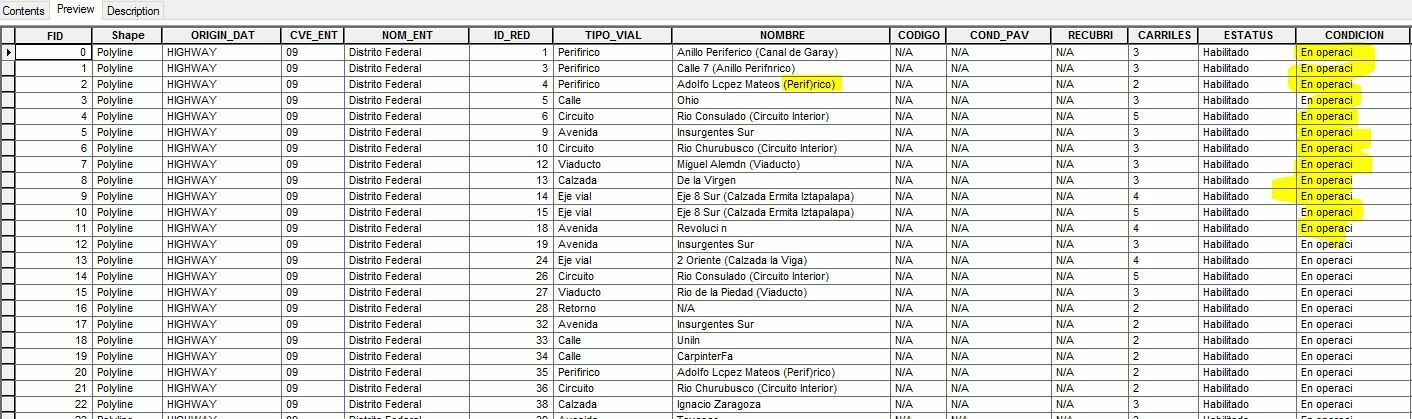
Here is a view of the shapefile attributes table in ArcCatalog:
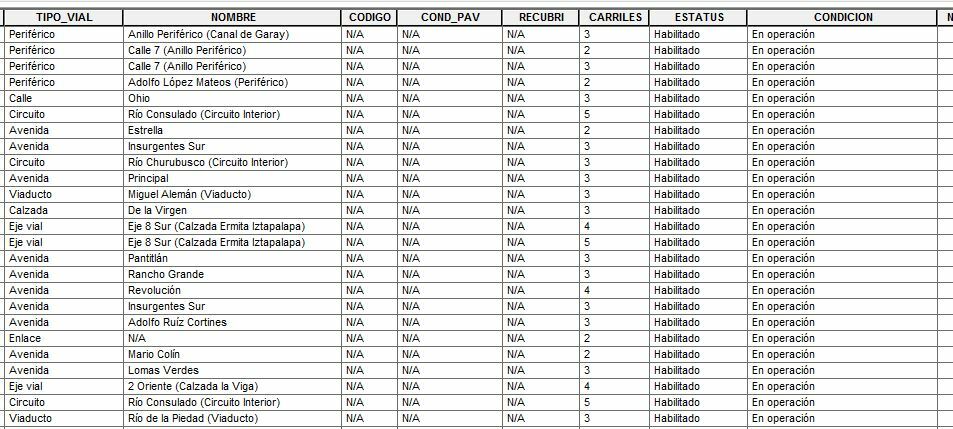
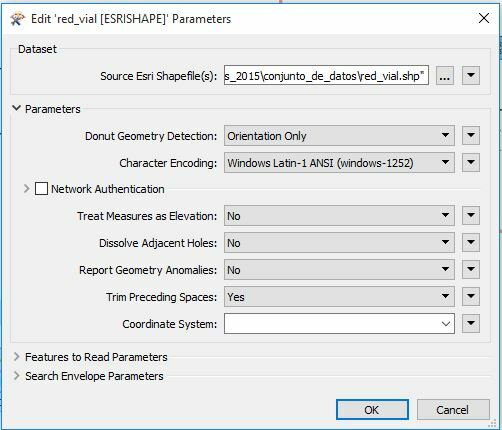
Here is a view of the shapefile through FME Inspector:
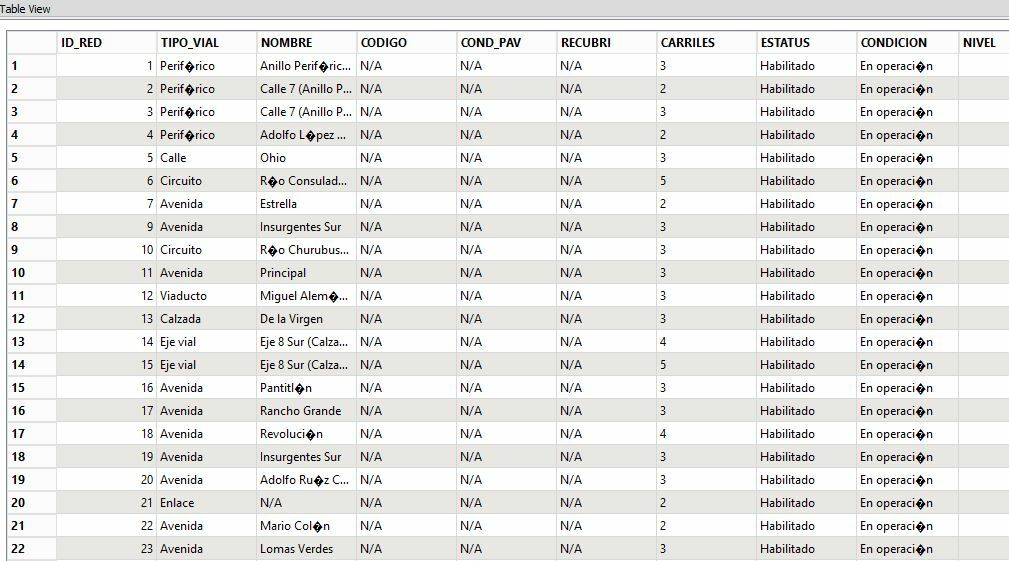
As you can see, FME does not seem to recognize Spanish characters. It hasn't been a problem for us when writing from shapefile directly into our Microsoft SQL database- we just updated user attribute types in the writer from varchar to nvarchar and it handled the character encoding issue perfectly. Shapefiles created in Spanish with ESRI and directly written to our SQL database using the method below retained their original character encoding.
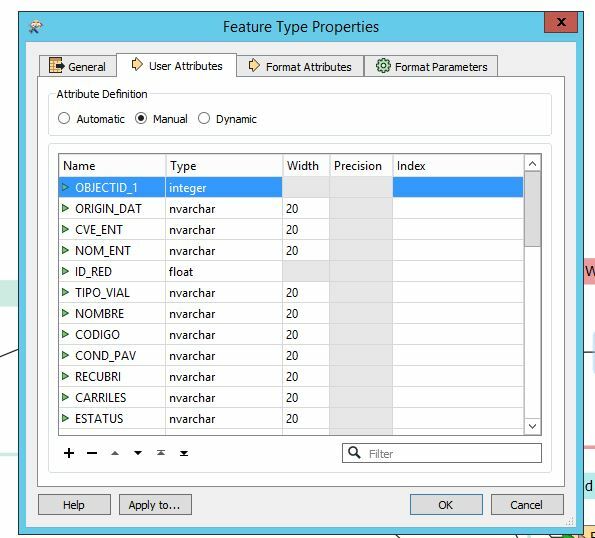
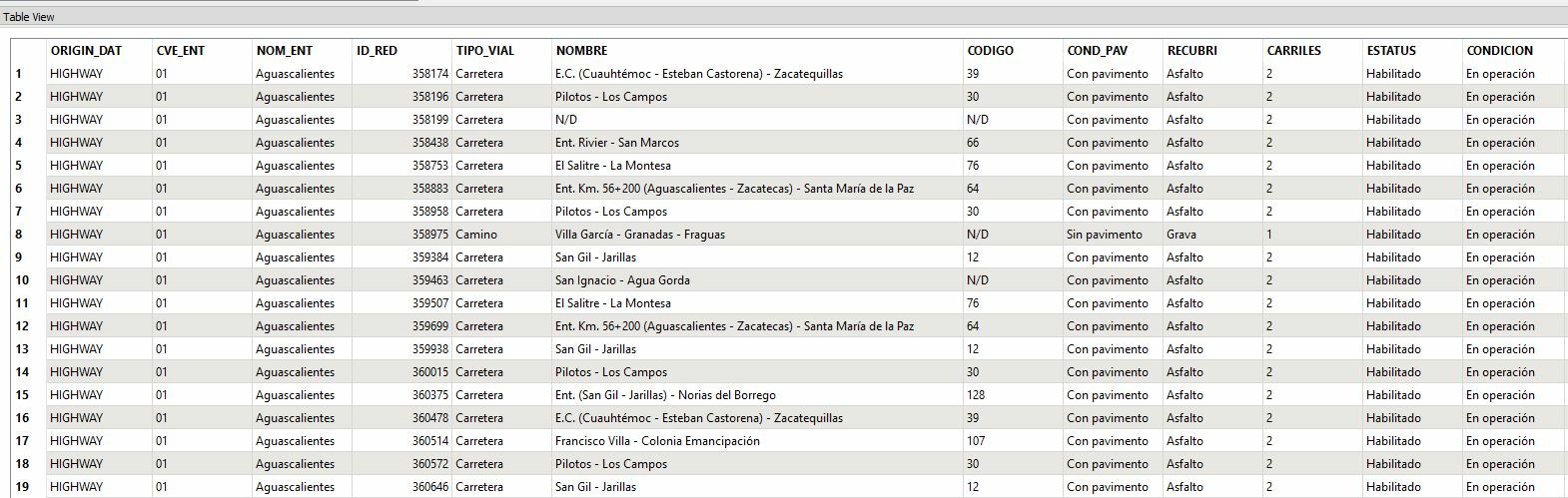
For another workflow, we needed to clip a large dataset (Highways covering all of Mexico) to smaller datasets (Highways clipped by state borders) so we used FME to perform our transformations. However, the result was a shapefile with unrecognizable characters within the attributes table.
When we attempted to write the new shapefiles created through FME to MySQL using a workflow identical to the one I described above, the unrecognizable characters were written to the database even after updating the attribute type column within the writer feature type properties.
So we've identified that FME is causing an issue but aren't sure how to update FME to handle these character encoding issues. Does anyone know how to get FME to recognize and properly handle these cases?