
I'm using a Spatial Filter and want to understand how the merge attributes element deals with multiple features.
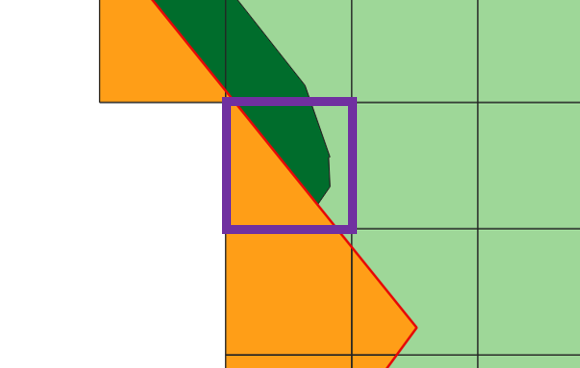
In the example attached the 'orange' grid is the candidate and the 'green' features the filter, with dark green feature A and light green feature B in that one dataset. For the highlighted purple square the following is true:
- The cell would pass, because it intersects the 'green' layer.
- It outputs the purple square attributes with the addition of A (dark green), (NOT B (light green))
My question is - How is it decided which attribute value from the 'green' data set is used (A or B)? the first it intersects, the largest feature or something else?
Apologies if this has been asked before I couldn't figure it out from the help file, or how best to pose the question on Google!
Thanks.


















