
Hey guys,
I am trying to merge these two data sets and aggregate based on field names. Is there a way I could do this in one process without having to merge first then add a new reader and aggregate.
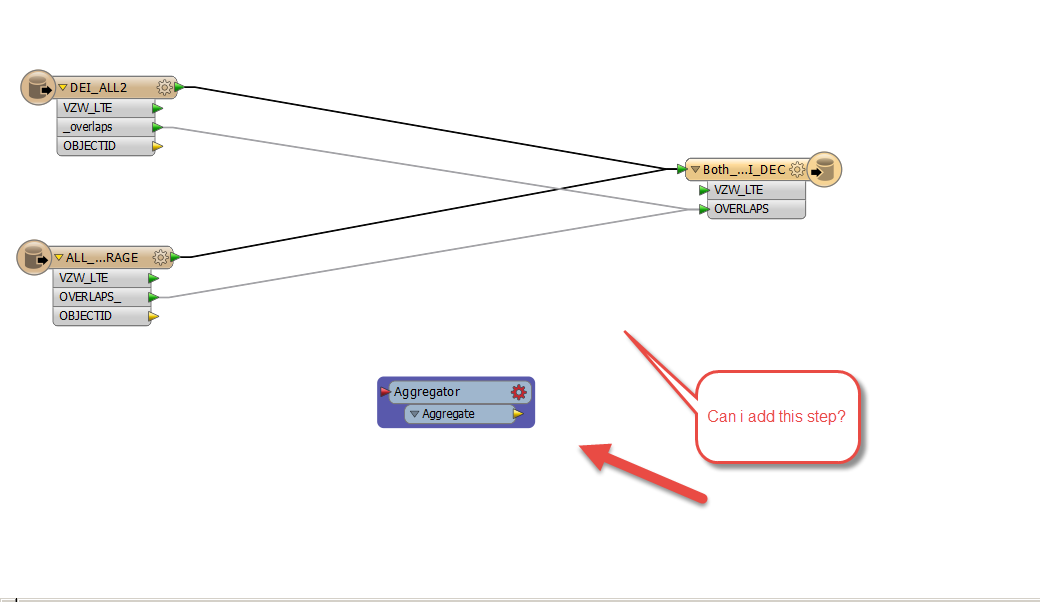

Hey guys,
I am trying to merge these two data sets and aggregate based on field names. Is there a way I could do this in one process without having to merge first then add a new reader and aggregate.
Best answer by david_r
You can just use an AttributeRenamer (or AttributeCopier, etc) to e.g. rename "_overlaps" on DEI_ALL_2 to "OVERLAPS_" before sending both feature types into the Aggregator.
The important thing is that the Group By attribute must have the same name on all the features that enter the Aggregator.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.





