Hi everyone,
I have to download all the features from an OData REST endpoint, but each request has a limit of 100,000 features (I expect there's 8 million or so in the full database).
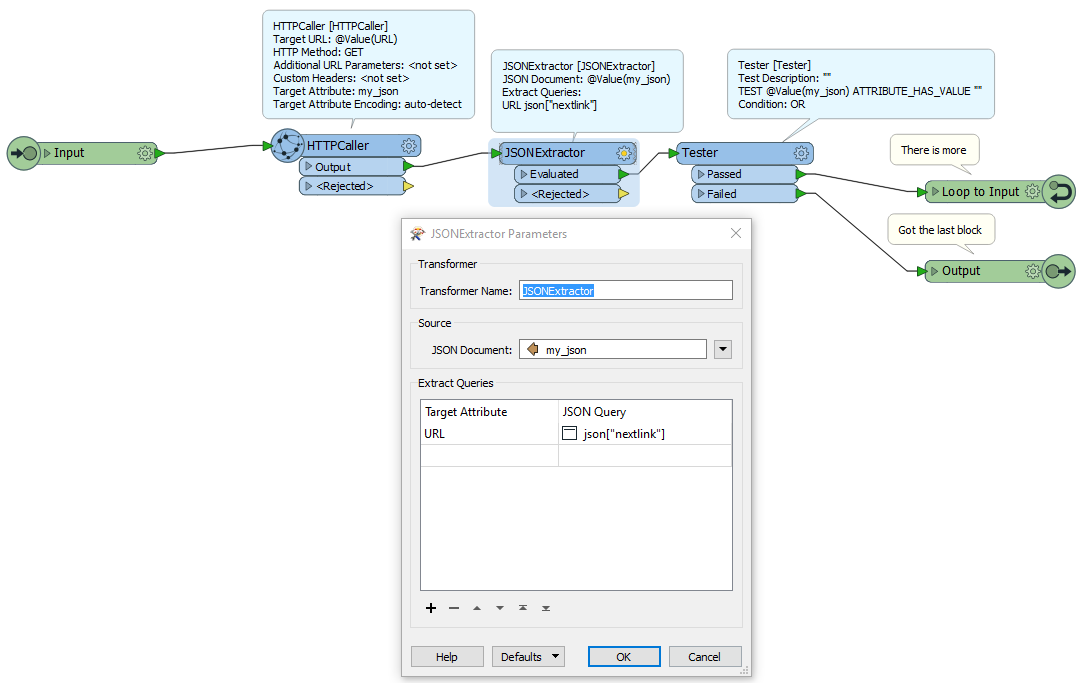
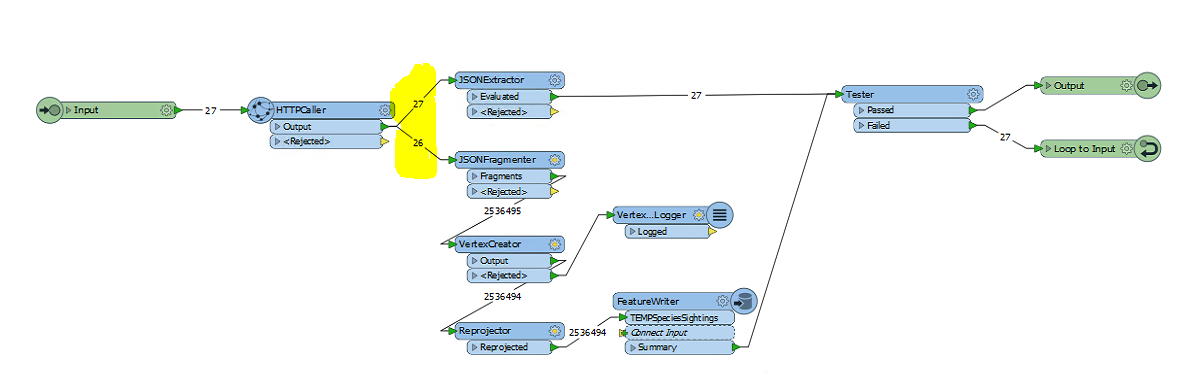
I've got the process working well with a JSON reader for the first request. But how do I loop so that I don't need 80 JSON readers?
Each time the service responds with a JSON object with its values and a "nextlink" if there are still more features that could be returned. If you then send the same request with a "$skip=100000" query parameter it sends the next 100,000 features.
I've experimented with an HTTPCaller in a custom transformer loop but I'm not familiar enough with FME to test for the existence of the "nextlink" attribute and then increment a skip counter by the number of features returned.
Thanks for your help everyone,
Aiden.