I have about 20 tables which I would like to do some data profiling on. I would like to generate a summary showing the percentage of null or empty values in each column.
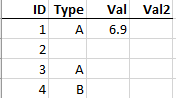
For example if the input table looks like this:
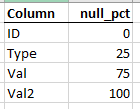
I would want an output like this:
I have played around with a few transformers like AttributeValidator, StatisticsCalculator and ListBuilder, but is PythonCaller really needed here?
I am using FME 2020
Thanks!
Best answer by ebygomm
Python is probably the most efficient way if you have lots of tables, but there are ways to do this without.
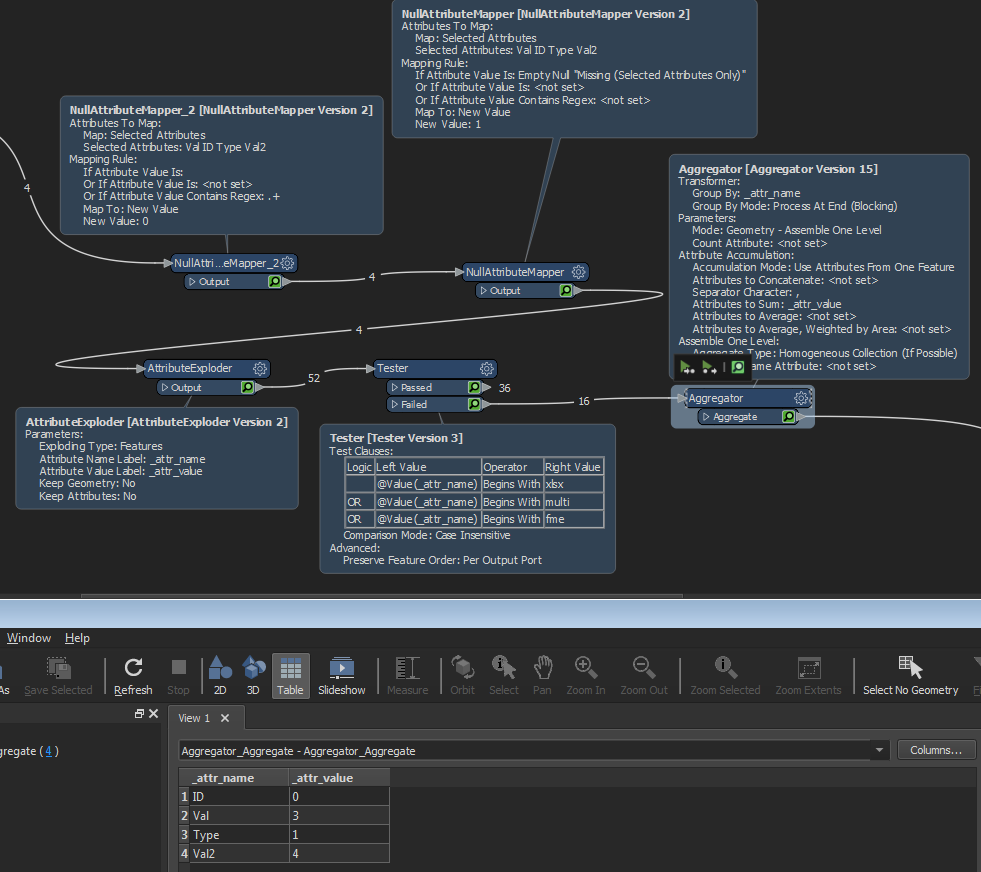
e.g. a null attribute mapper to map all values to 0, a second to map all null values to 1 (edited for accuracy), an attributeexploder then an aggregator on AttributeValue and sum the values
Or after the null attribute mappers you could use a statistics calculator to sum the values and then pivot the output
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
If your backend database support SQL, that would be my preferred solution as it would be an order of magnitude quicker than doing it in FME, especially for larger tables. You can use the SQLExecutor in FME to get the results back into FME.
For example you could use the "Schema (any format)" reader to retrieve all the tables and column names, then send them to the SQLExecutor.
Example SQL:
SELECT COUNT(1) AS TotalRowCount ,COUNT(myColumn) AS TotalNotNull ,COUNT(1) - COUNT(myColumn) AS TotalNull ,100.0 * COUNT(myColumn) / COUNT(1) AS PercentNotNull FROM myTable
This calculates the percentage of records where column myColumn is not null in table myTable.
Python is probably the most efficient way if you have lots of tables, but there are ways to do this without.
e.g. a null attribute mapper to map all values to 0, a second to map all null values to 1 (edited for accuracy), an attributeexploder then an aggregator on AttributeValue and sum the values
Or after the null attribute mappers you could use a statistics calculator to sum the values and then pivot the output
Python is probably the most efficient way if you have lots of tables, but there are ways to do this without.
e.g. a null attribute mapper to map all values to 0, a second to map all null values to 1 (edited for accuracy), an attributeexploder then an aggregator on AttributeValue and sum the values
Or after the null attribute mappers you could use a statistics calculator to sum the values and then pivot the output
This is a great answer. I think you meant "a null attribute mapper to map all values to 0, a second to map all null values to 1". I hadn't realised that NullAttributeMapper could use a regex to process everthing that isn't null or empty.
One problem I found in the solution was the need to use Selected Attributes on NullAttributeMapper in order to process the "missing values". I found that I then needed a new transformer for every input table. I got around this by first converting all the data to SQLite, which then I think uses proper nulls rather than Missing.
This is a great answer. I think you meant "a null attribute mapper to map all values to 0, a second to map all null values to 1". I hadn't realised that NullAttributeMapper could use a regex to process everthing that isn't null or empty.
One problem I found in the solution was the need to use Selected Attributes on NullAttributeMapper in order to process the "missing values". I found that I then needed a new transformer for every input table. I got around this by first converting all the data to SQLite, which then I think uses proper nulls rather than Missing.
Yes, map all null values to 1, I've edited the answer now, thanks
If your backend database support SQL, that would be my preferred solution as it would be an order of magnitude quicker than doing it in FME, especially for larger tables. You can use the SQLExecutor in FME to get the results back into FME.
For example you could use the "Schema (any format)" reader to retrieve all the tables and column names, then send them to the SQLExecutor.
Example SQL:
SELECT COUNT(1) AS TotalRowCount ,COUNT(myColumn) AS TotalNotNull ,COUNT(1) - COUNT(myColumn) AS TotalNull ,100.0 * COUNT(myColumn) / COUNT(1) AS PercentNotNull FROM myTable
This calculates the percentage of records where column myColumn is not null in table myTable.
I got interested again in this solution, since as you point out, it would scale up quite well. However it doesn't seem to work with SQLite. My input data is mainly spreadsheets and Esri shapefile - its easy to add FeatureWriter to convert to SQLite Non Spatial .
Here is my SQL from the SQLExecutor - I need a different SQL for each column so I have substituted the column name in. What I think happens is that SQLExecutor deals with this correctly where the substution string is in place of a SQL expression, but not in place of schema strings such as COUNT(column_name).
SELECT '@Value(_attr_name)' AS AttrName ,COUNT(1) AS TotalRowCount ,COUNT('@Value(_attr_name)') AS TotalNotNull ,COUNT(1) - COUNT('@Value(_attr_name)') AS TotalNull ,100.0 * COUNT('@Value(_attr_name)') / COUNT(1) AS PercentNotNull FROM "ForumExample"
I got interested again in this solution, since as you point out, it would scale up quite well. However it doesn't seem to work with SQLite. My input data is mainly spreadsheets and Esri shapefile - its easy to add FeatureWriter to convert to SQLite Non Spatial .
Here is my SQL from the SQLExecutor - I need a different SQL for each column so I have substituted the column name in. What I think happens is that SQLExecutor deals with this correctly where the substution string is in place of a SQL expression, but not in place of schema strings such as COUNT(column_name).
SELECT '@Value(_attr_name)' AS AttrName ,COUNT(1) AS TotalRowCount ,COUNT('@Value(_attr_name)') AS TotalNotNull ,COUNT(1) - COUNT('@Value(_attr_name)') AS TotalNull ,100.0 * COUNT('@Value(_attr_name)') / COUNT(1) AS PercentNotNull FROM "ForumExample"
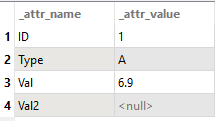
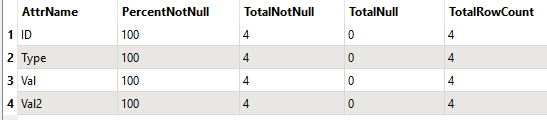
Here is the table leading into my SQL Executor
And this is what I get out:
Indeed, you need to put double quotation marks around the column references (attribute names) inside the COUNT functions. If not, they'll be interpreted by SQLite as string literals rather than column references.
SELECT '@Value(_attr_name)' AS AttrName ,COUNT(1) AS TotalRowCount ,COUNT("@Value(_attr_name)") AS TotalNotNull ,COUNT(1) - COUNT("@Value(_attr_name)") AS TotalNull ,100.0 * COUNT("@Value(_attr_name)") / COUNT(1) AS PercentNotNull FROM "ForumExample"
This is a great answer. I think you meant "a null attribute mapper to map all values to 0, a second to map all null values to 1". I hadn't realised that NullAttributeMapper could use a regex to process everthing that isn't null or empty.
One problem I found in the solution was the need to use Selected Attributes on NullAttributeMapper in order to process the "missing values". I found that I then needed a new transformer for every input table. I got around this by first converting all the data to SQLite, which then I think uses proper nulls rather than Missing.
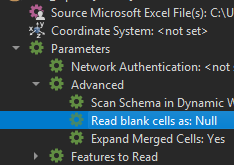
As an aside, there is a setting when reading Excel files that allows you to map empty cells to null values instead of missing
I got interested again in this solution, since as you point out, it would scale up quite well. However it doesn't seem to work with SQLite. My input data is mainly spreadsheets and Esri shapefile - its easy to add FeatureWriter to convert to SQLite Non Spatial .
Here is my SQL from the SQLExecutor - I need a different SQL for each column so I have substituted the column name in. What I think happens is that SQLExecutor deals with this correctly where the substution string is in place of a SQL expression, but not in place of schema strings such as COUNT(column_name).
SELECT '@Value(_attr_name)' AS AttrName ,COUNT(1) AS TotalRowCount ,COUNT('@Value(_attr_name)') AS TotalNotNull ,COUNT(1) - COUNT('@Value(_attr_name)') AS TotalNull ,100.0 * COUNT('@Value(_attr_name)') / COUNT(1) AS PercentNotNull FROM "ForumExample"
Here is the table leading into my SQL Executor
And this is what I get out:
Thank you - your SQL works, I hadn't appreciated that subtlety about the single versus double quotes