



I am trying to create a workspace to read the contents of an Excel file from SharePoint directly into memory to then operate on, rather than download the file to a temporary location first.
I understand that I should be able to read files to memory by using the SharePointOnlineConnector with 'Action: Download' and 'Download as: Attribute' settings, and have had a degree of success with a simple text file that I'm using for test purposes.
The '_contents' attribute returns the full content of my text file, as below:
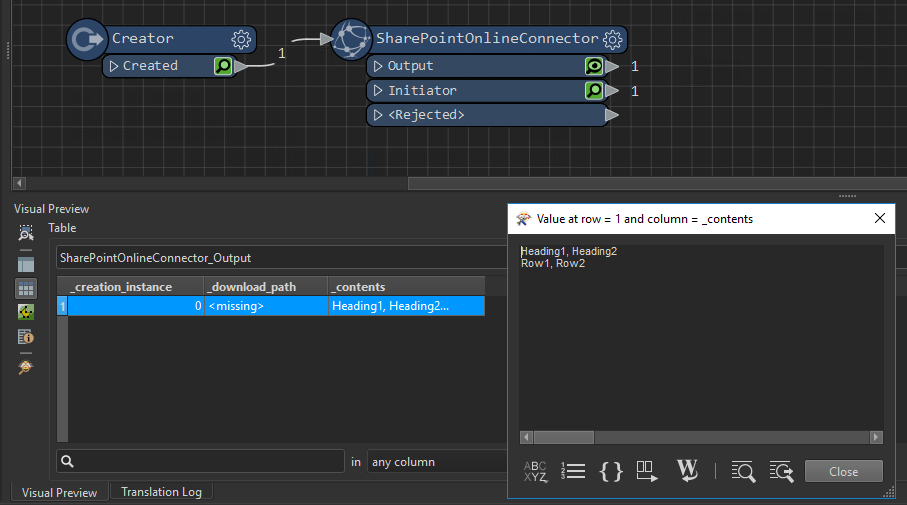 However, I'm not sure how to deal with this attribute to make it usable after this point…
However, I'm not sure how to deal with this attribute to make it usable after this point…
I've tried passing the '_contents' attribute to a CSV FeatureReader as the 'Dataset', but this didn't work, as the reader tries to open a file at the location specified within that attribute. I guess I've already read the CSV file with the SharePointOnlineConnector, so now need to work with the attribute directly...
Reading an Excel file from SharePoint seems to work the same way, although the '_contents' attribute is more obtuse. I can only assume that it represents the contents of the Excel file in some way:
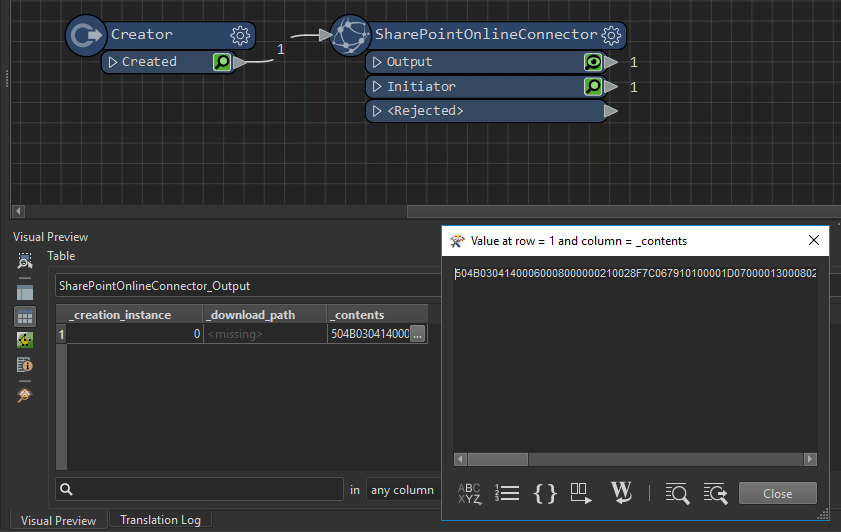
Clearly the Connector is working, but how do I make the '_contents' attribute useful?




