


OK, so technically this comes from a much older question, but someone recently asked for further assistance on there, so here we go...
Question of the WeekThe original question was...
Q) I have a shapefile of points and 103 rasters. I wanna overlay the points on the 103 rasters and extract the values to attributes. The final aimed result is the shapefile containing 103 additionnal attributes with extracted values, I want also that attributes have the same names as the rasters. Is there any way to do this batch process?
I tried to load all the rasters into the PointOnRasterOverlayer but it seems that it connot do a batch process but work only on a single raster at once.
And then this week @fmenoob asked for some assistance in setting up the answer.
A) There are a couple of solutions here. One is is sort of similar to the previous question-of-the-week on parallel processing with the ShortestPathFinder because groups are needed and one way is to create duplicates of the points. Another way would be to do a point-in-polygon to find which points are grouped to which rasters. But the simplest way - if we restrict the scenario a little - is to simply mosaick all the raster features together.
Let's take a look at these techniques...
The ProblemFirst let's see the problem. In my example there are multiple rasters and multiple points (centre points of parks). If I try to do the overlay then I get this...
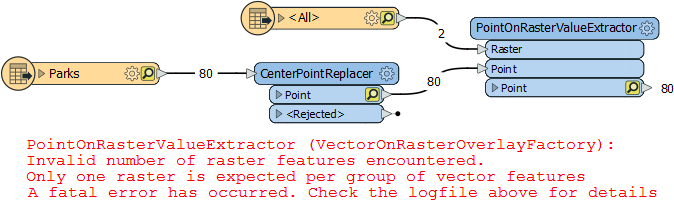
It's because the transformer (now renamed to PointOnRasterValueExtractor) is designed to not try every point against every raster. It must have one raster (and only one raster) per group of points.
I can't even put all the rasters into one group, with a common key, like this:

One raster, one group. That's the rule.
The thinking is probably that iterating through all possible combinations would cause performance issues, but whatever the reason for this limitation, let's see how to resolve it...
Solution 1This is the simplest solution. We put a RasterMosaicker transformer into the raster stream:
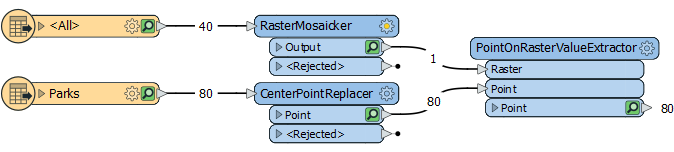
Now the workspace is happy. It has one big raster and one set of point features. We're all good.
There are two limitations here:
- You can't have overlapping rasters, unless you have an idea of how to blend the overlaps together.
- You won't get the name of the raster file (as asked in the original question) on the point features.
So, can we do this with fewer limitations...
Solution 2One improvement is to actually group the points to the rasters. We can achieve this by doing a pre-processing overlay of the data. We take the outline of the rasters and overlay the points to see which raster each falls inside. That becomes the group...
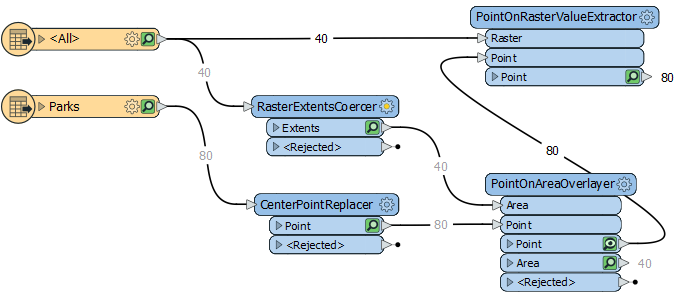
So we take the extents of each raster (RasterExtentsCoercer) and overlay the points against them, making sure to have Merge Attributes active.
This passes over the name of the source raster, by default as the attribute fme_basename. So all I have to do is use Group-By fme_basename in the PointOnRasterValueExtractor.
We've solved the limitation of getting the name of the raster file, but we still have the limitation that overlapping rasters would be potentially problematic. We wouldn't be able to guarantee what happens if a point fell into that overlap.
Let's see how to resolve that...
Solution 3The way to resolve this is to create duplicate copies of the point features, as the original answer to this question specified.
It would look like this...
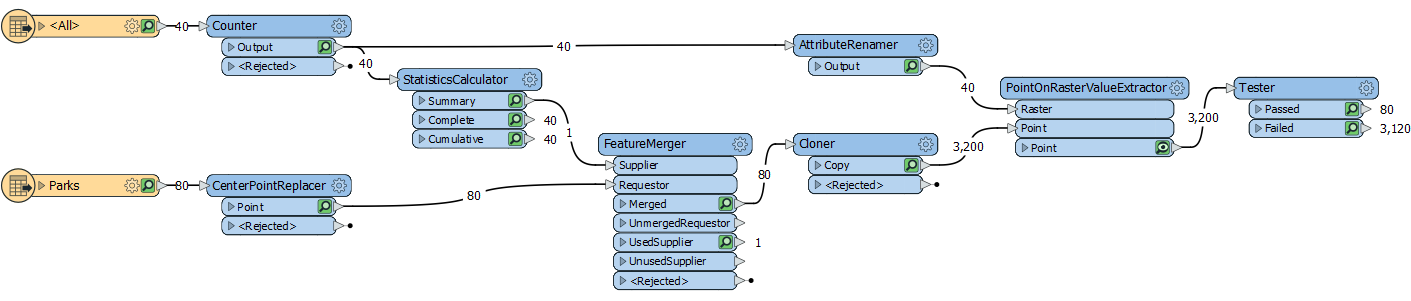
As you can see, it's a bit more complicated. It's more complicated because I'm doing a complete solution (as I'll explain later) but here's how it works:
- We give a unique ID to each raster feature (Counter transformer)
- We calculate the maximum ID value (StatisticsCalculator)
- We merge that maximum ID on to the point features (FeatureMerger)
- We create one copy of each point per raster; i.e. we create Max ID copies (Cloner)
- We rename the ID to the same as the Clone number (AttributeRenamer)
- We carry out the PointOnRasterValueExtraction
- We test for and filter out points that didn't fall inside a raster feature (Tester)
The final Tester tests for an fme_basename value. If it doesn't have one, then it falls outside of the raster in its group and can be ignored. I have 80 features output showing that each point only fell inside a single raster. If I had overlapping raster boundaries, and a point fell inside both rasters, then I'd get an extra feature out of the Tester:Passed port.
The reason I say this is a complete solution is because I don't need to know the number of raster features in advance. If I did know there were 40 then I wouldn't need to count them, and could remove the StatisticsCalculator and FeatureMerger, and just create 40 clones.
ReviewSo there we are. This is a good example of how there are often different ways to achieve the same task in FME, but each way has its own limitations and benefits.
If your raster features don't overlap, then Solution #2 is probably the best one to go for.
If you would like to see the workspaces, you can get them , and , and To actually run the workspaces you'll need the standard FME dataset (see safe.com/fmedata).
Other Notable QuestionsHere are some other notable questions for this week...
- I mentioned License Borrowing in a quiz question recently, and now @map_monster would like to make use of it.
- The key is to ensure your license is set up to allow borrowing, and you can get in touch with your FME sales contact to check that.
- @orkunkocaturk wants to know how do you deal with a web service that returns dates in a long string of numbers that are not an obvious date format.
- @ebygomm notes that these are seconds (or milliseconds) and suggests a strategy for handling these using the %s flag
- @lucasoertli wonders how to handle attributes that are read in lowercase but written in UPPERCASE
- I just wanted to point out this question about an error message about coordinate systems appearing in 2019.2. If you experience the problem, do let me know, so I can pass it on to development. I expect this one to be fixed for 2020.
- There are some beginners struggling here, here, and here. I'm going to escalate these within our support group, but if anyone has a few minutes to show some love to these new users, then it would be appreciated all around.
Have a great weekend folks. It's a holiday day on Monday in Canada, so I'll be back with the quiz on Tuesday of next week.
Cheers
Mark

