


I have geodatabases, which can contain strictly structured data of linear utilies and related objects, such as powerlines, utility poles etc. However, geodatabase sometimes contains only powerlines, sometimes only poles, sometimes powerlines, poles, power plants and more. So, one geodatabase may contain two layers of data with strict and specific names and attributes, the other may contain all of defined layers, and so on.
I convert this geodatabase into an XML file through XMLTemplater provided with an input from XSD file. Since the structure of the geodatabase is always the same, XML Templater allows me to set the template beforehand, and XMLTemplater just writes the attributes afterwards.
The reduced ROOT template looks something like this:
<?xml version="1.0" encoding="UTF-8"?>
<geodatabase:Utilities xmlns:gss="http://www.isotc211.org/2005/gss" xmlns:xsi= ... namespaces etc.>
<geodatabase:Data>
<geodatabase:PowerLines>
<pwrlns:GeneralInfo ... />
<pwrlns:Objects>
{fme:process-features("SUB_POWERLINES")}
</pwrlns:Objects>
</geodatabase:PowerLines>
<geodatabase:UtilityPoles>
<utilpol:GeneralInfo ... />
<utilpol:Objects>
{fme:process-features("SUB_UTILITY_POLES")}
</utilpol:Objects>
</geodatabase:UtilityPoles>
</geodatabase:Data>
</geodatabase:Utilities>Read data is processed through sub-templates, so in case that there are both powerlines and utility poles in the geodatabase, the result could look something like this:
<?xml version="1.0" encoding="UTF-8"?>
<geodatabase:Utilities xmlns:gss="http://www.isotc211.org/2005/gss" xmlns:xsi= ... namespaces etc.>
<geodatabase:Data>
<geodatabase:PowerLines>
<pwrlns:GeneralInfo ... />
<pwrlns:Objects>
<pwlrns:Object>
<attr:lineID>128</attr:lineID>
<attr:desc>damaged section</attr:desc>
</pwlrns:Object>
<pwlrns:Object>
<attr:lineID>149</attr:lineID>
<attr:desc>attention required</attr:desc>
</pwlrns:Object>
</pwrlns:Objects>
</geodatabase:PowerLines>
<geodatabase:UtilityPoles>
<utilpol:GeneralInfo ... />
<utilpol:Objects>
<utilpol:Object>
<attr:pointID>4812</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
<utilpol:Object>
<attr:pointID>7445</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
</utilpol:Objects>
</geodatabase:UtilityPoles>
</geodatabase:Data>
</geodatabase:Utilities>So each unique powerline segment and pole are put into an Object, which is nested in Objects. This is the result I want and am happy with.
THE PROBLEM
The problem lies in the way the XML file is created. If my geodatabase contained only powerlines, the result would look like this:
<?xml version="1.0" encoding="UTF-8"?>
<geodatabase:Utilities xmlns:gss="http://www.isotc211.org/2005/gss" xmlns:xsi= ... namespaces etc.>
<geodatabase:Data>
<geodatabase:PowerLines>
<pwrlns:GeneralInfo ... />
<pwrlns:Objects>
<pwlrns:Object>
<attr:lineID>128</attr:lineID>
<attr:desc>damaged section</attr:desc>
</pwlrns:Object>
<pwlrns:Object>
<attr:lineID>149</attr:lineID>
<attr:desc>attention required</attr:desc>
</pwlrns:Object>
</pwrlns:Objects>
</geodatabase:PowerLines>
<geodatabase:UtilityPoles>
<utilpol:GeneralInfo ... />
<utilpol:Objects>
</utilpol:Objects>
</geodatabase:UtilityPoles>
</geodatabase:Data>
</geodatabase:Utilities>So there is an empty header for non-existent utility poles. I was quite happy with being able to convert the geodatabase into XML, and since I do this export only several times a month, it is not a big deal to manually remove the empty sections. But it would be nice to automate the process in a way that if there isn't an utility poles layer, the header is not written into the XML file at all.
I hit a dead end trying to come up with a conditional if-else solution, where I put the header into a separate sub-template, and that sub-template was run on condition that there existed a specifically named layer for utility poles (as I said, naming and everything is strictly set, so data can be separated with attribute filter, see the picture below).
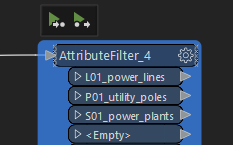 This either didn't work, or worked in a way that data was redundant, because the header was written that many times, as there were the objects (see below, all data including the header is written twice).
This either didn't work, or worked in a way that data was redundant, because the header was written that many times, as there were the objects (see below, all data including the header is written twice).
<?xml version="1.0" encoding="UTF-8"?>
<geodatabase:Utilities xmlns:gss="http://www.isotc211.org/2005/gss" xmlns:xsi= ... namespaces etc.>
<geodatabase:Data>
<geodatabase:PowerLines>
...
</geodatabase:PowerLines>
<geodatabase:UtilityPoles>
<utilpol:GeneralInfo ... />
<utilpol:Objects>
<utilpol:Object>
<attr:pointID>4812</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
<utilpol:Object>
<attr:pointID>7445</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
</utilpol:Objects>
</geodatabase:UtilityPoles>
<geodatabase:UtilityPoles>
<utilpol:GeneralInfo ... />
<utilpol:Objects>
<utilpol:Object>
<attr:pointID>4812</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
<utilpol:Object>
<attr:pointID>7445</attr:pointID>
<attr:desc>"status unknown"</attr:desc>
</utilpol:Object>
</utilpol:Objects>
</geodatabase:UtilityPoles>
</geodatabase:Data>
</geodatabase:Utilities>Is there even a way to do this? If-else conditions would probably work if there was a variable created for every layer in the geodatabase based on their existence. Then, the sub-template would evaluate the variable, and if it the value confirmed the layer's existence, the header would be created and data written.
I'd appreciate any help and will try to provide more info, if my description of the problem is not clear enough.


