")
Hi!
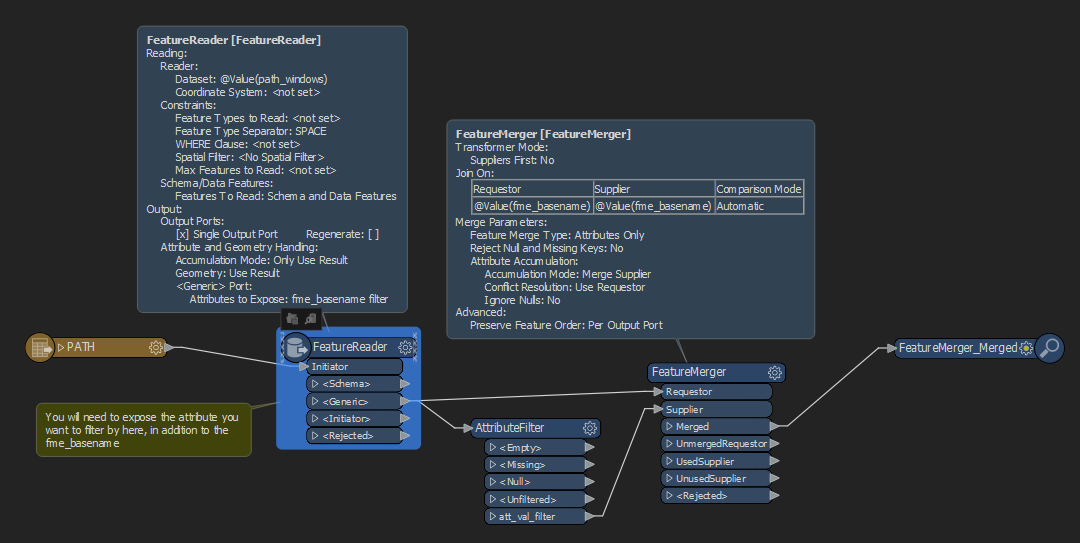
Here's an overview of what I'd like to achieve:
- User selects a folder.
- FME reads in all the files plus those in sub folders.
- An attribute filter filters out those files required. The attributes to filter by will have already been set.
- Selected files are then read into workspace and processing continues.
(all files are either .csv, .xls or .xlsx)
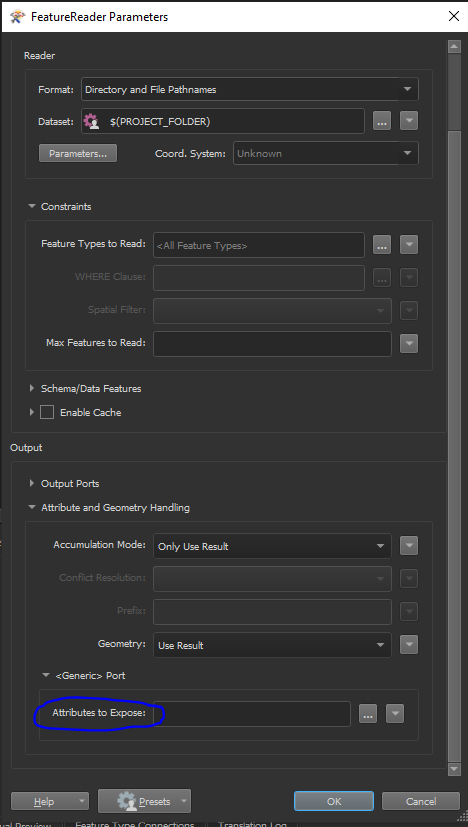
Having read this post this user is trying to accomplish the same thing. But I am unable to set up the FeatureReader to read the contained data in a file.
Please can you let me know how to do this or is there a better method? Thanks.