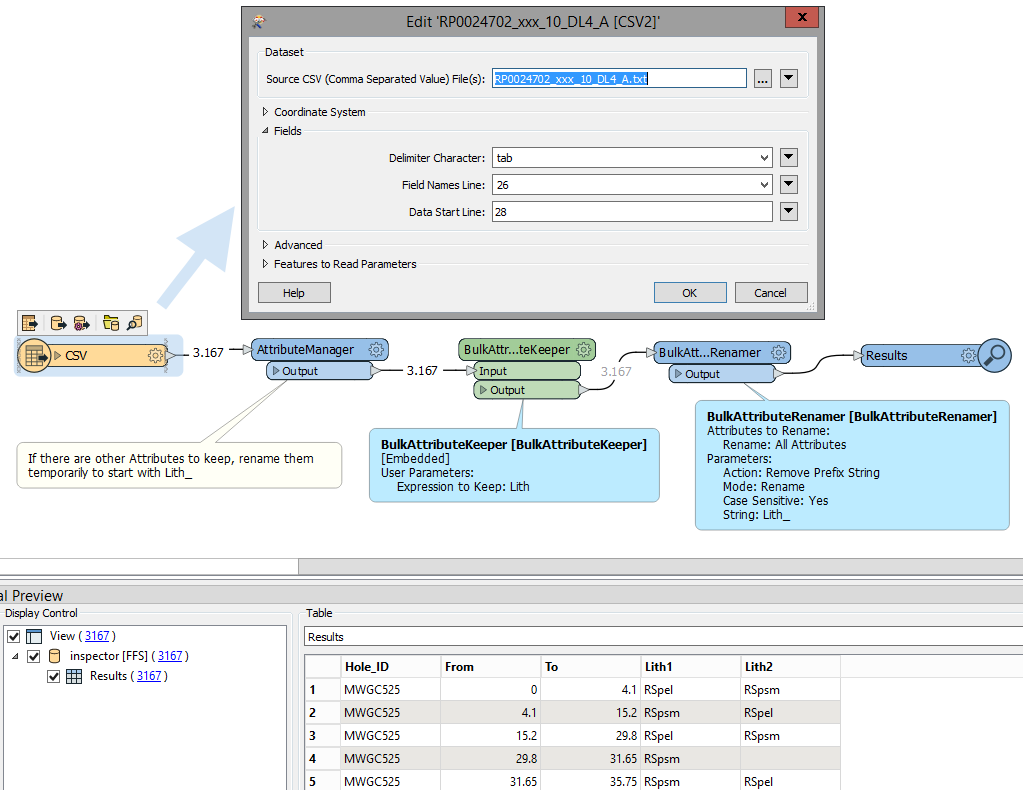
I am trying to use the Attribute filter to only see the columns i'm interested in (those containing the text 'lith') and using it's _element_index to filter the columns (lists). Its not working and I'd like some help or advice on better ways to solve this problem. The job will read in a database table of values to check against, but i'm not there yet as I first need to find / isolate the relevant columns of interest.
I attach the text file & workbook for reference
Thanks



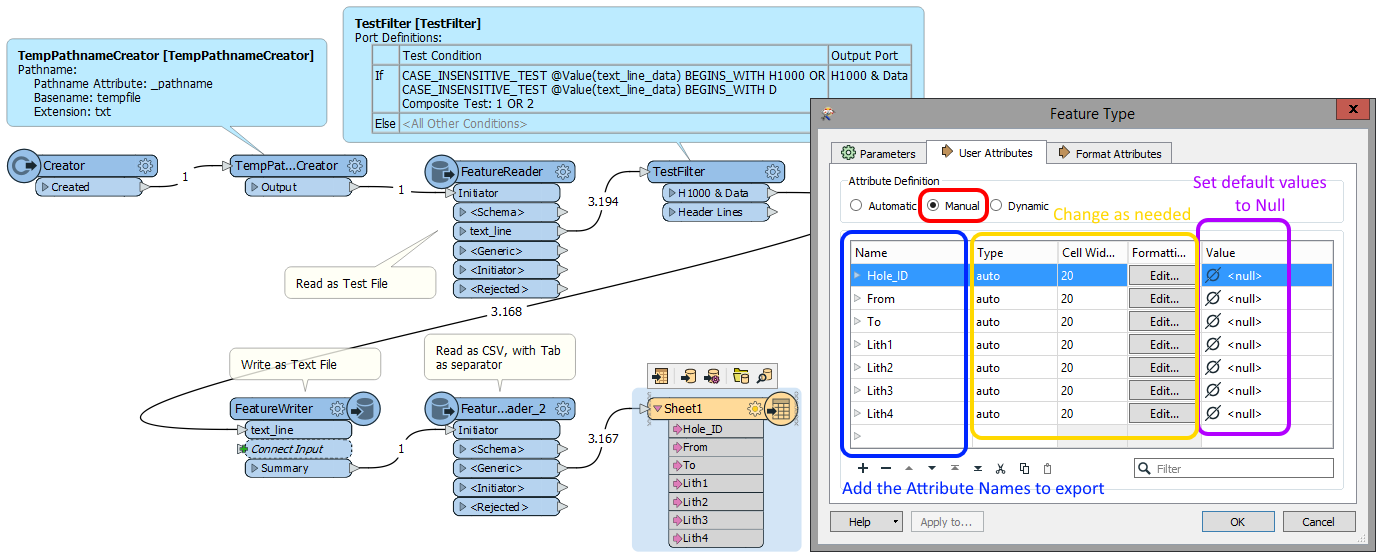 Also see the attached workspace.
Also see the attached workspace.