
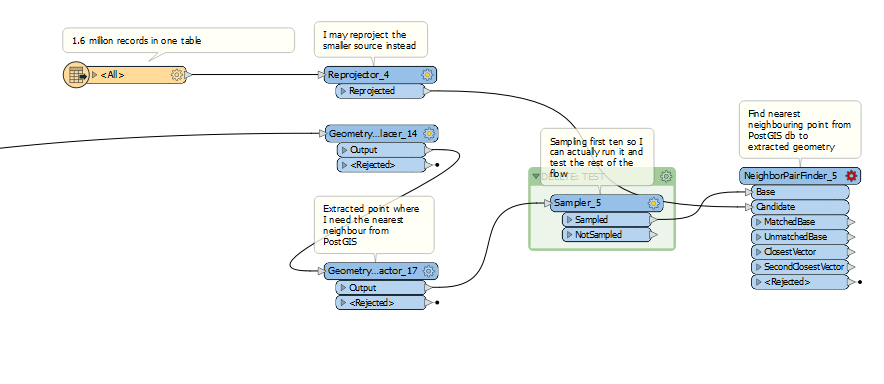
Another learning FME question:
I have a postGIS table with 1.6million records.
I have 264 features from a lot of post process from another dataset.
Each 264 features have been split to 4 extent coordinates.
I need to understand the nearest neighbouring shape from the 1.6 million record PostGIS database (single table) for each 4 coordinates.
This means that FME Desktop attempts to cache the 1.6 million PostGIS records so it can then complete the nearest neighbour checks. I get 25% of the way through before I run out of memory and to be perfectly honest, I am slightly impressed my dinky laptop got this far.
How would I go about changing this flow to increase performance?
Many thanks