
I have 3 shapefiles and and 1 spreadsheet I need to import into 1 PostgreSQL/PostGIS table
ADM1_area (Shapefile) is linked to the spreadsheet via a name column however due to differences in spellings this may need manual intervention
How Do I bring up both the Shapefile name column and the spreadsheet name column and where necessary manually map the values across the two?
for instance
MyPlace = My Place (Or one source might have diacritics )
This is probably a manual process as REGEX would take to long
The preferred name spelling will then map to the name column in PG table and all other spelling concatenate to a list in alt_names column
The other 2 shapfiles are ADM2_area and ADM2_point
these form 1 database row that has both geometry and point_geometry columns and are linked to the ADM1_area row via ADM1_name column this needs to be the same name used before and may need intervention
When I created the PostGIS connection I could only see how to had 1 geometry column not two?
Thank You
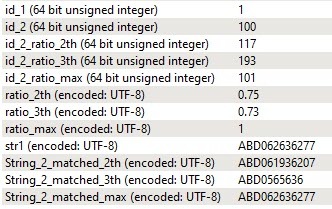 str1 is the Input1 string to be compared.
str1 is the Input1 string to be compared. 