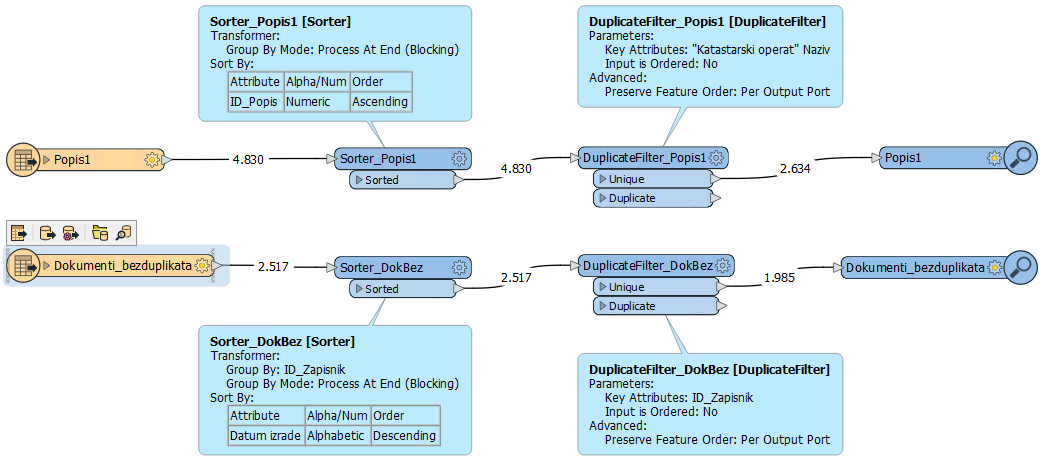
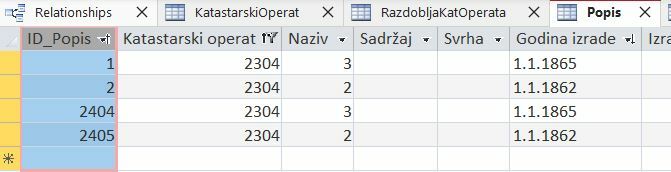
So, in the "List" table, I have, as far as I've seen, some duplicate entries. For example, in this image, rows with ID 2404 and 2405 are duplicates of IDs 1 and 2. I believe I have duplicate entries for all lists like that. Could someone help with how to solve this, or rather, how to delete duplicate entries?
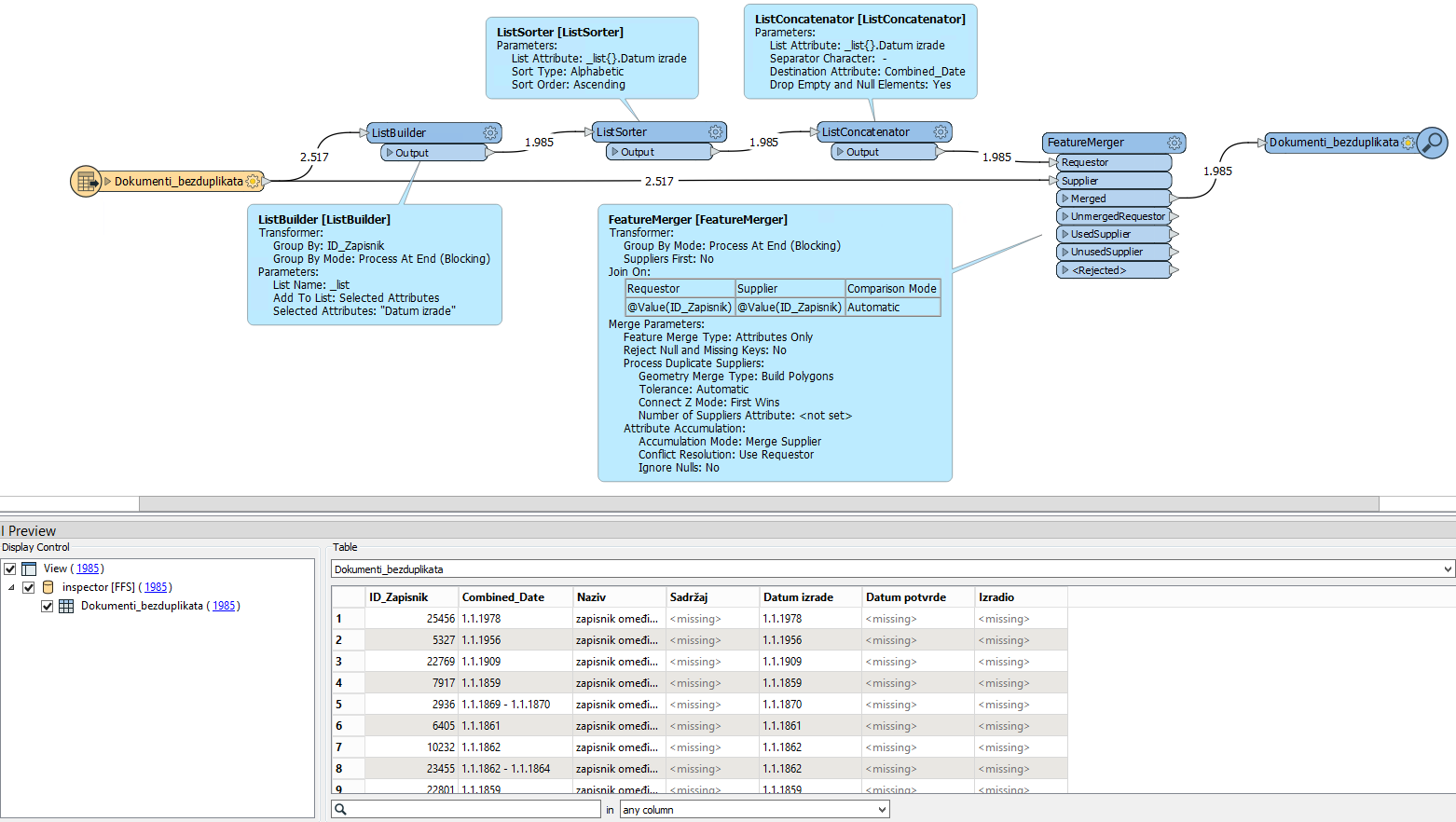
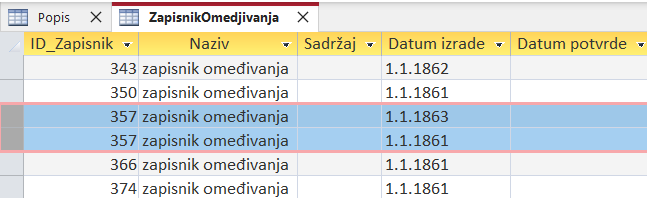
 In the "RecordBoundaries" table, I must not have records with the same ID. I should do the following only for duplicate IDs because they belong to the same document: for example, let ID_Record 357 be one record, and the "creation date" is always an older date (January 1, 1861), while for the "confirmation date," the attribute from the duplicate record should be used (January 1, 1863). So, the process should be done only for duplicate IDs because there must be one record each for themselves.
In the "RecordBoundaries" table, I must not have records with the same ID. I should do the following only for duplicate IDs because they belong to the same document: for example, let ID_Record 357 be one record, and the "creation date" is always an older date (January 1, 1861), while for the "confirmation date," the attribute from the duplicate record should be used (January 1, 1863). So, the process should be done only for duplicate IDs because there must be one record each for themselves.
 P.S. I have attached both files, "Popis" and "ZapisnikOmedjivanja," so you can immediately try with them and send back the edited files to me.
P.S. I have attached both files, "Popis" and "ZapisnikOmedjivanja," so you can immediately try with them and send back the edited files to me.
Best regards.