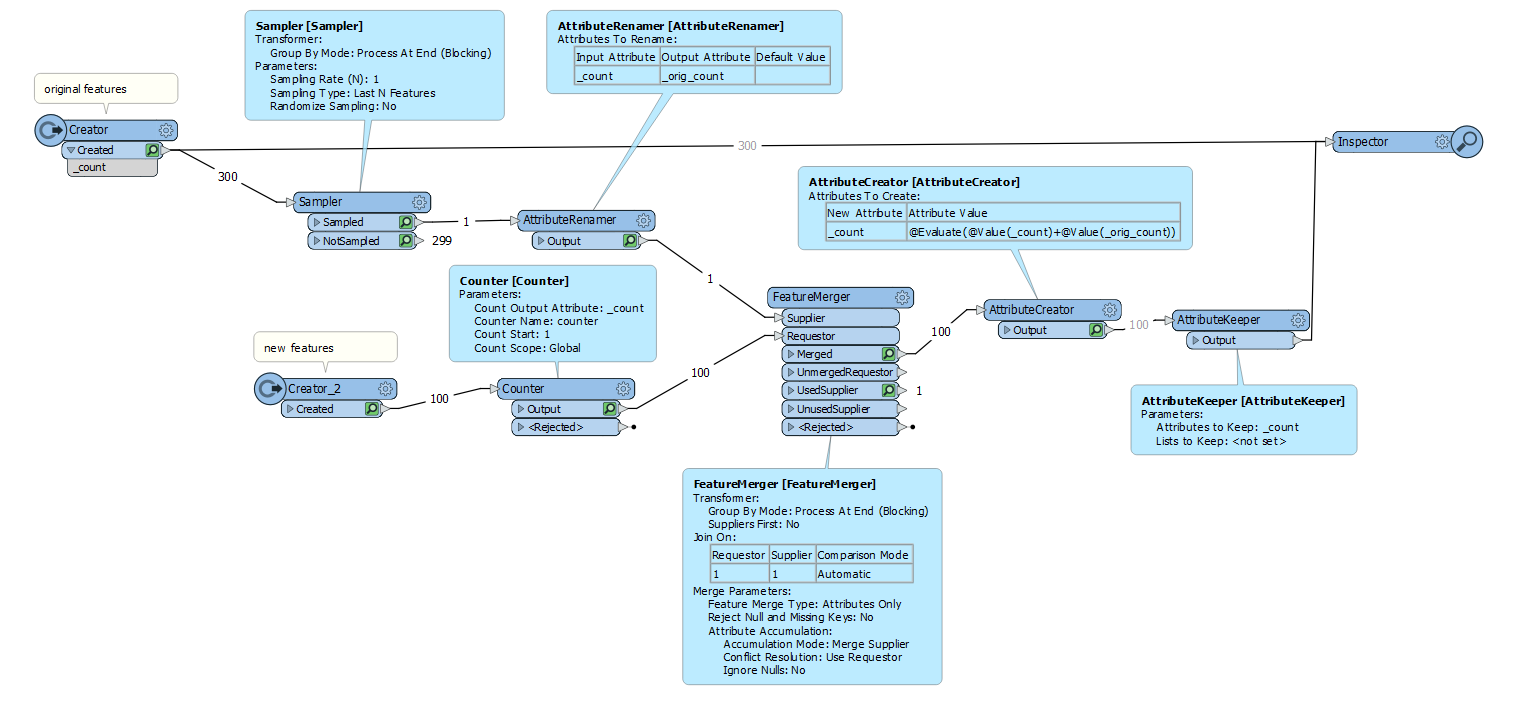
I am looking to see if there is a method of setting a 'continuation' for counting features in FME.
Essentially I have 300 features with a UID of a simple number (1,2,3 etc). I wanted to see if there was a way for when I add additional features into the mix, the UID would automatically populate continuing with the next available UID (i.e. 301)