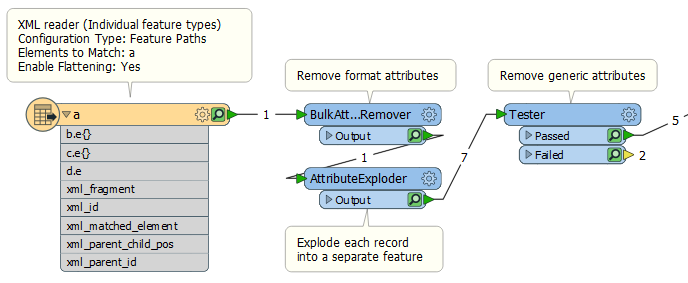
I have some XML data in the structure
<a>
<b>
<e>data1</e>
<e>data2</e>
</b>
<c>
<e>data3</e>
<e>data4</e>
</c>
<d>
<e>data5</e>
</d>
</a>I would like one feature for every 'e' element, which is simple enough using Feature Paths by setting the elements to match parameter to e on the XML Reader.
What I haven't been able to figure out is how to indicate which parent it belongs to. (data1, data2 is b, data3,data4 is c, data5 is d).
Adding Ancestor Elements (Parent) in the XML Flatten Options doesn't help because there are no attributes associated with b,d,e.
Even if if set the elements to match to a/b/e a/c/e a/d/e explicitly rather than just e, the xml_matched_element is still just e.
I can't guarantee the order of the parent nodes, so using the xml_id is not an option either.


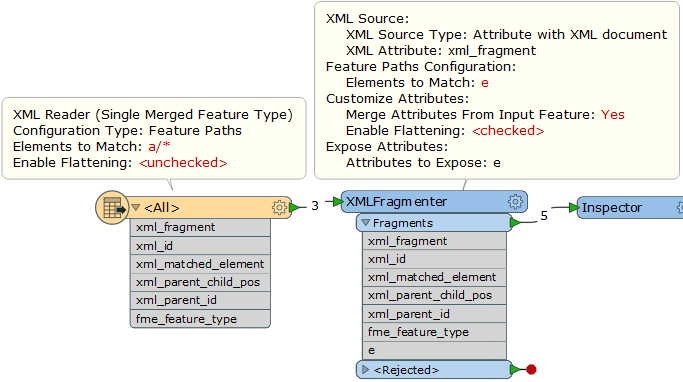
")