I have a request to build a FME workspace that can read a text file and load it into an Oracle database with the filename with a suffix appended as the table name (ie. filename_ext).
That is fine, the problem is the column headers and fields will differ, depending on the filetype (file A might have 10 columns, file B will have 17 and the column names will be different between A and B)
I’ve considered using a tester that directs the flow to an attributemanager based on a “user parameter”. This becomes problematic if the source text file changes column structure or an additional file type (file C, D and E) is introduced.
Is there a way for the text file to be read (as generic in the featurereader), have the attributes exposed, split and output with the 1st row as the column headers. Ideally without having to know the column names prior.
Thanks
Thomas
Best answer by todd_davis
Lots of options here. Basically you are wanting to use a dynamic writer and pass a schema into it to set the output schema. You do not need to expose the attributes in the workspace.
As for reading the layer, a simple CSV reader using an “auto” delimiter character (reading the text file) going out via single Outport Port (Generic port). You have the schema coming out of the featurereader as well, or you might want to use the SchemaScanner (example in the dynamic documentation above).
You can use the attached example to read your file and see the results like shown below.
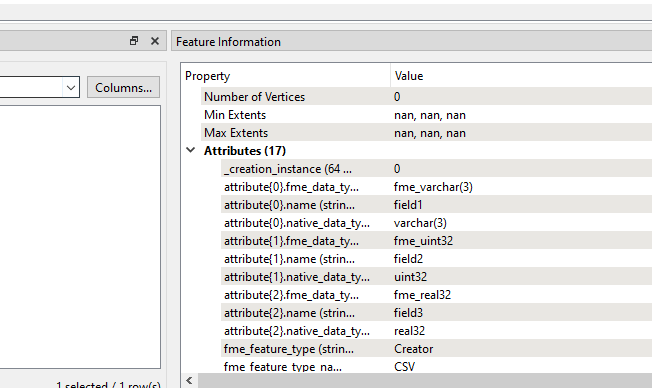
Here is an example of me reading a file and you can see the schema and data (by using feature information...it is not exposed in the workspace or in the visual preview)
This post is closed to further activity.
It may be an old question, an answered question, an implemented idea, or a notification-only post.
Please check post dates before relying on any information in a question or answer.
For follow-up or related questions, please post a new question or idea.
If there is a genuine update to be made, please contact us and request that the post is reopened.
Lots of options here. Basically you are wanting to use a dynamic writer and pass a schema into it to set the output schema. You do not need to expose the attributes in the workspace.
As for reading the layer, a simple CSV reader using an “auto” delimiter character (reading the text file) going out via single Outport Port (Generic port). You have the schema coming out of the featurereader as well, or you might want to use the SchemaScanner (example in the dynamic documentation above).
You can use the attached example to read your file and see the results like shown below.
Here is an example of me reading a file and you can see the schema and data (by using feature information...it is not exposed in the workspace or in the visual preview)