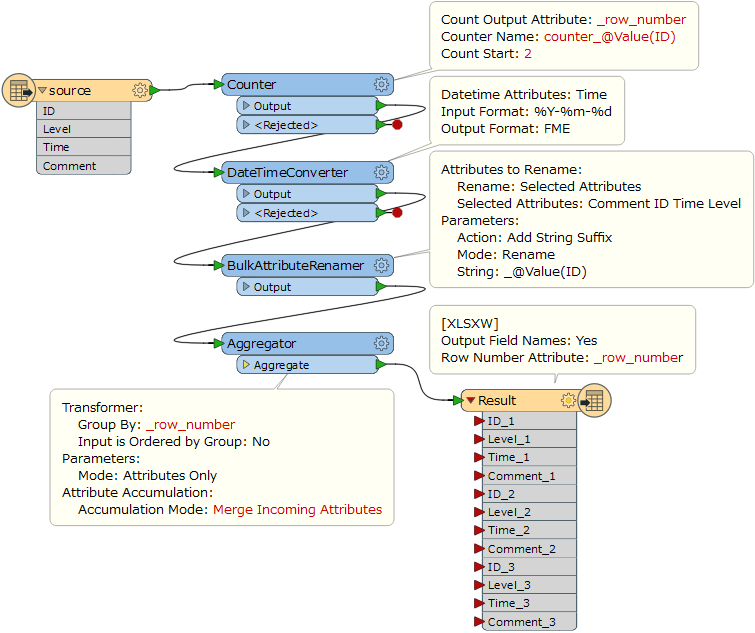
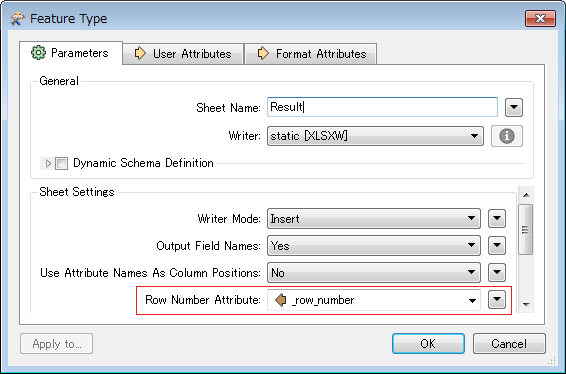
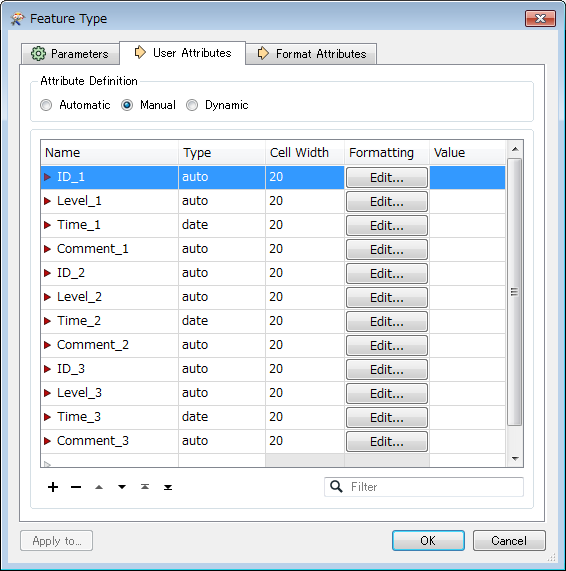
This is what I have
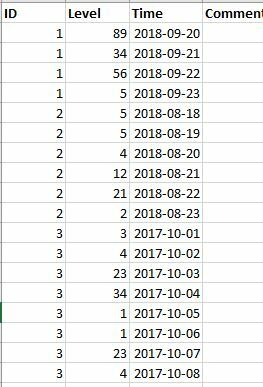
This is what I need
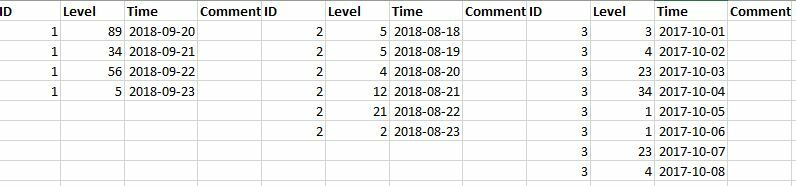
As you can see I need to transpose the ID but retaining the rest. I am unsure how to phrase the question so I guess the images shows my problem better than my phrasing!
My table has more than thousand records and I tried many combinations of sorter, counter, attributeexploader and so on until the point that I am very confused as how to even approach this in FME. Any suggestions are appreciated! And yes, I'm very new to FME. Output should be a csv but that is less of a concern right now.