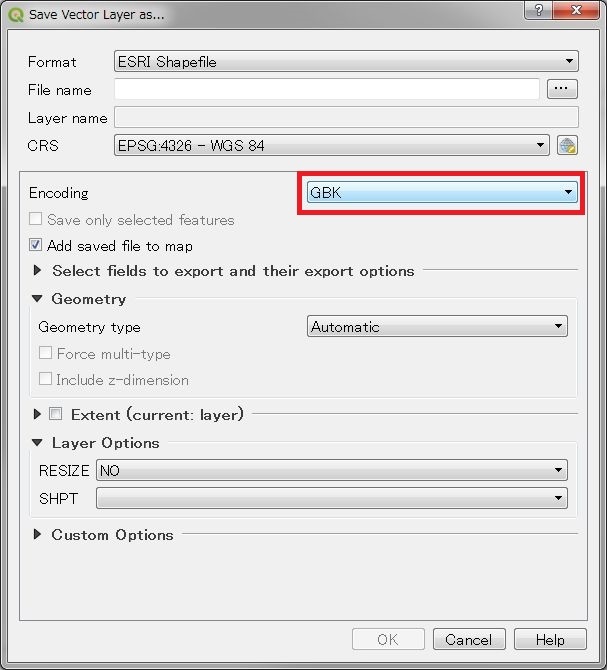
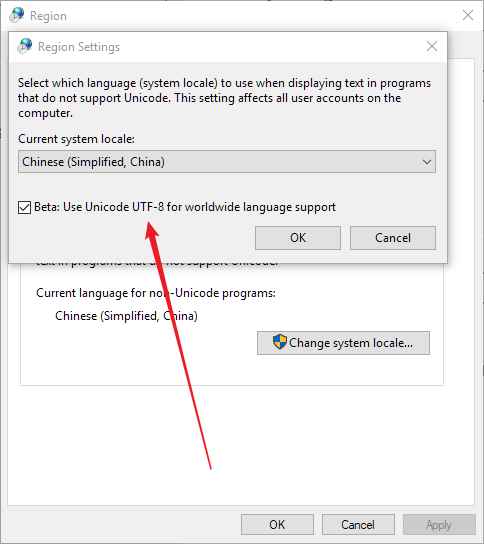
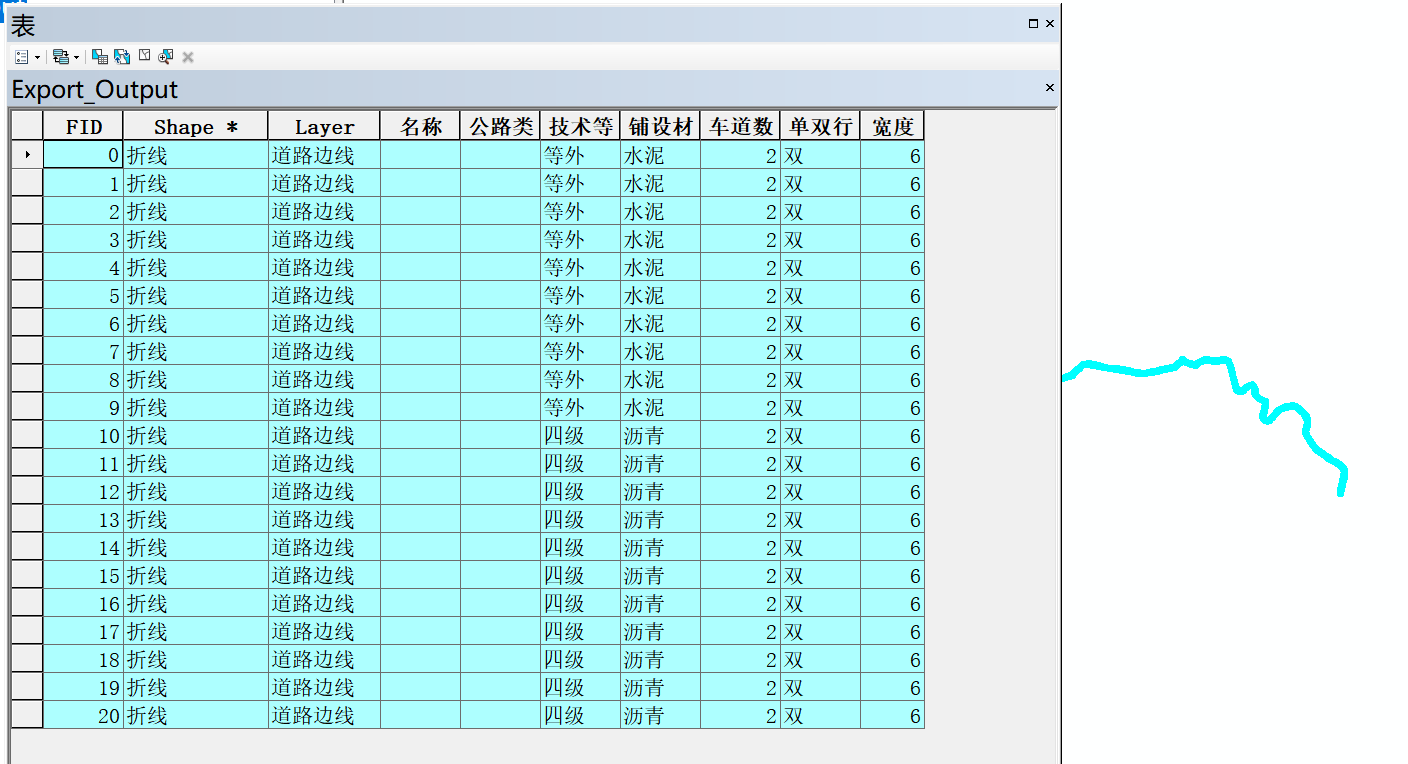
There is messy code when I open a shapefile created by arcgisdesktop, but it shows well in arcgisdesktop. I don't know why.
I hope someone can help me to solves this problem , thanks a lot.
Here is the testfile.
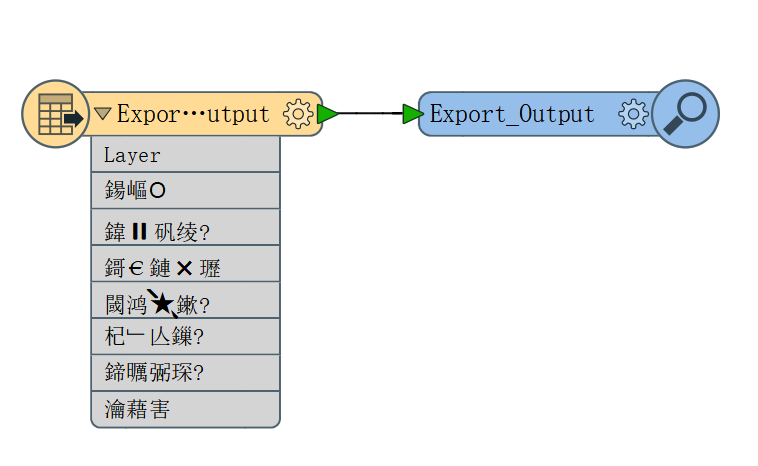
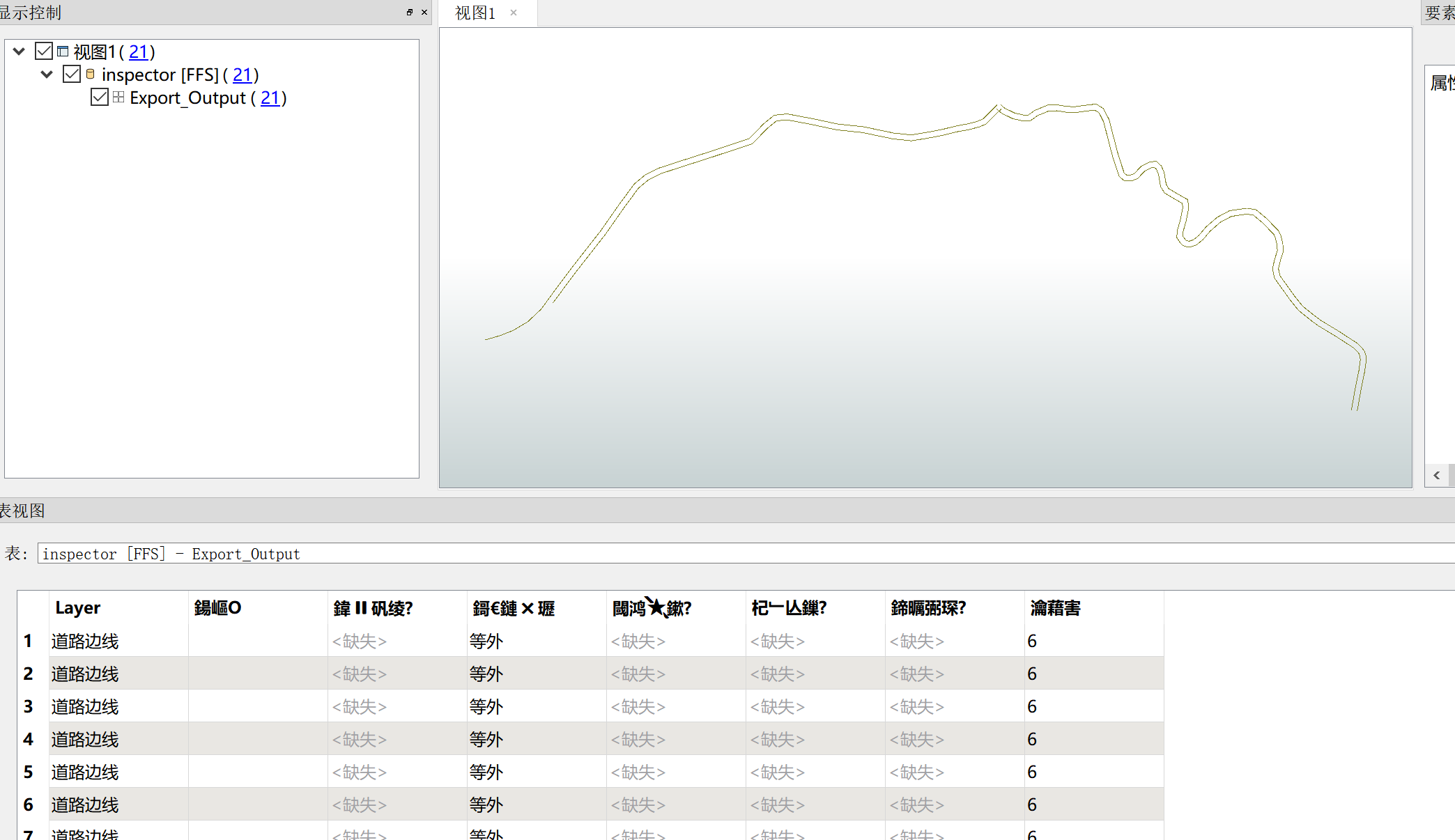


") +2
+2There is messy code when I open a shapefile created by arcgisdesktop, but it shows well in arcgisdesktop. I don't know why.
I hope someone can help me to solves this problem , thanks a lot.
Here is the testfile.
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.