I have a response from Azure's OCR service, which looks like this (full response attached):
{
"language": "en",
"orientation": "Up",
"textAngle": 0,
"regions": [
{
"boundingBox": "316,555,1597,123",
"lines": [
{
"boundingBox": "1515,555,398,29",
"words": [
{
"boundingBox": "1515,555,82,23",
"text": "CRMA"
},
{
"boundingBox": "1608,555,154,29",
"text": "Completion"
},
{
"boundingBox": "1775,555,138,23",
"text": "Document"
}
]
},
{
"boundingBox": "316,632,556,46",
"words": [
{
"boundingBox": "316,632,233,46",
"text": "As-built"
},
{
"boundingBox": "570,632,302,46",
"text": "Certificate"
}
]
}
]
},
and so on.
I wish to concatenate the text of "words" with spaces, within "lines" separated by a single newline, within "regions" separated by 2 newlines, into a single attribute, so the above snippet would look like
CRMA Completion Document
As-built CertificateI'm new to the json transformers and seem to be going around in circles with this. How can I do it?
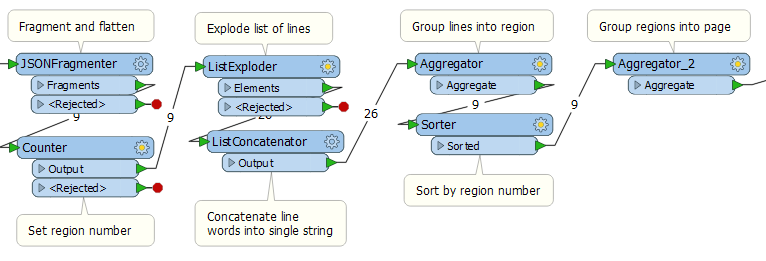
At the moment I have three JSONFragmenters chained together, then I have three Aggregators chained together (see ) It seems a bit awkward.
")