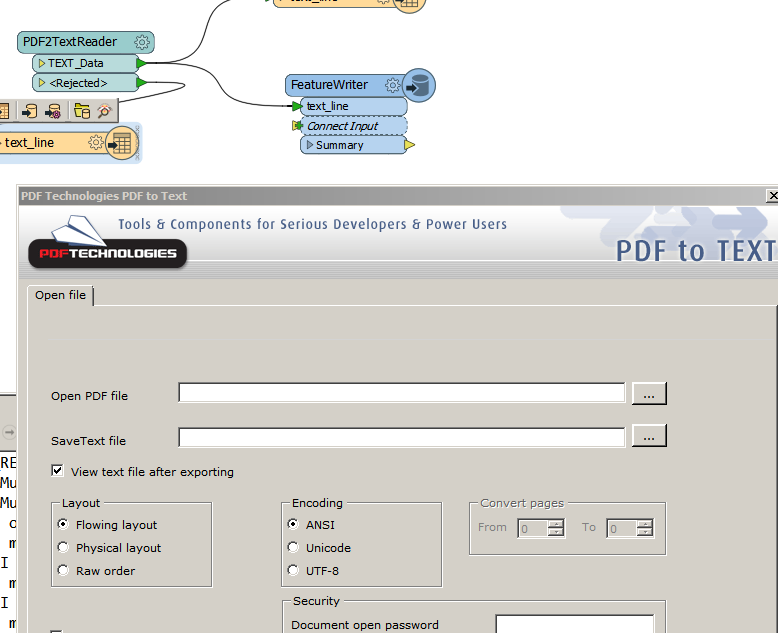
I'm struggling to transform some pdfs. I am using the PDFtoTEXT transformer as well as a textwriter, stringsearcher, maybe calling to python, and then writing it to a database. I'm flummoxed at the first step.
Sometimes it'll write a pdf to a textfile. But often the pdf2text program box pops up. That's useless for automation. What I want is for it to read a whole folder of texts - found the place to specify that - and process each of them into a complex row in my database with many different values. The pdf contains a couple values in the headers and many more in a table-like layout. I will need a couple string parsing processes to get through all that. No idea how to get it to read the pdf name and put that in one cell in my db.
But the data inspectors are useless. The interface says the transformation was successful - but nothing was written to the output.txt.
So - issues:
- how to process multiple texts
- how to see what's going on so I know it's working properly
- how to write to my database.
I understand textfiles and regex. That's not the problem. FME is driving me nuts. I am trying to learn FME.
Thanks,
Marsh