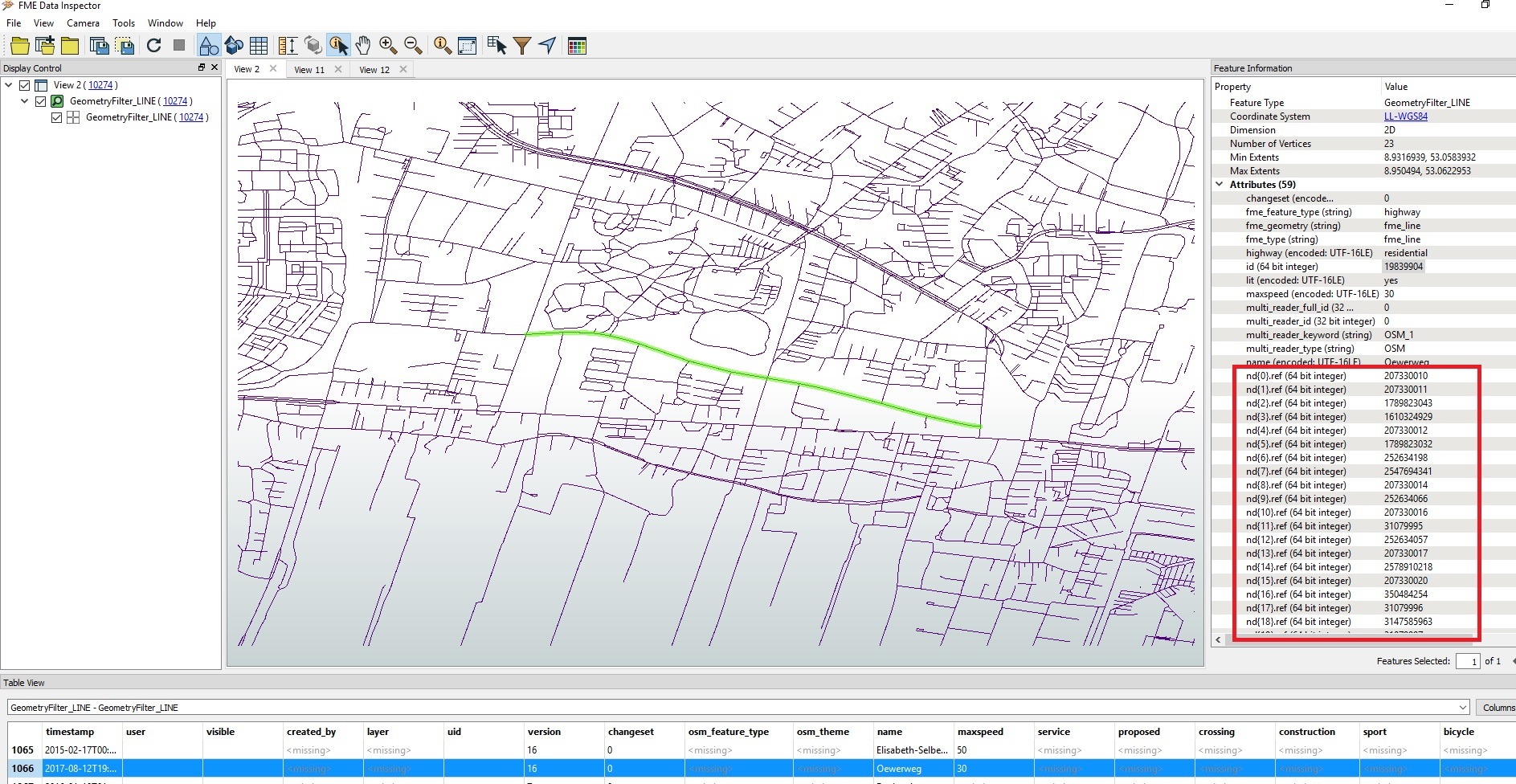
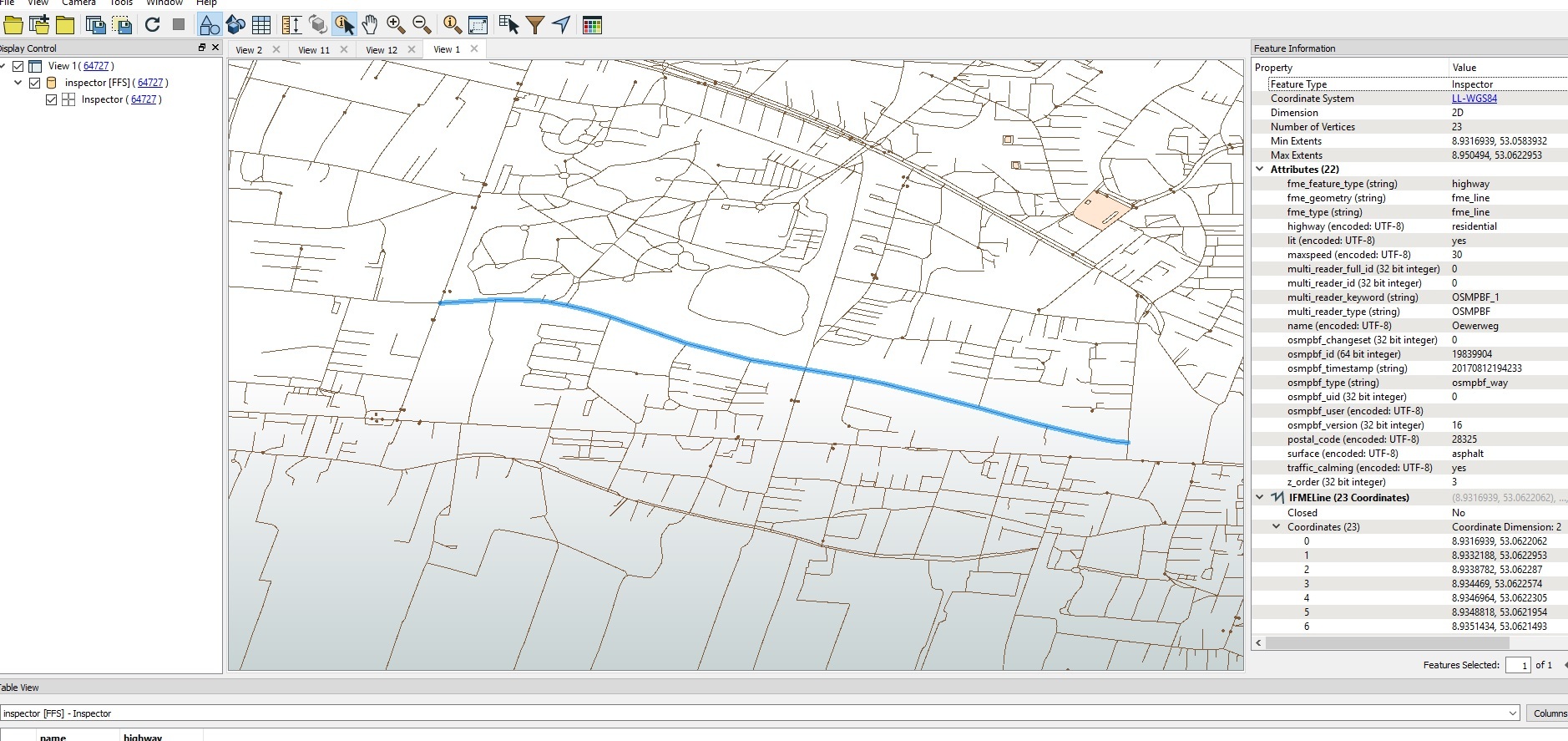
I'm using the OSM PBF reader in FME 2018 to extract highways. I want to split the highway lines into segements, so that each line only contains 2 vertices (the "from node id" and "to node id"). What I am interested in are the underlying node ids.
I've tried reading the PBF, both as OSM feature types and primitive types, but neither seems to expose the underlying node ids.
I can get to the node ids using the OSM XML Reader, but the XML file is far larger and I will need to process the whole road network for Europe, hence the use of PBF.
Looking at the forum seems to suggest that either it's not currently supported or to use Python.
Is there a simple way to expose the underlying node ids using the PBF reader?