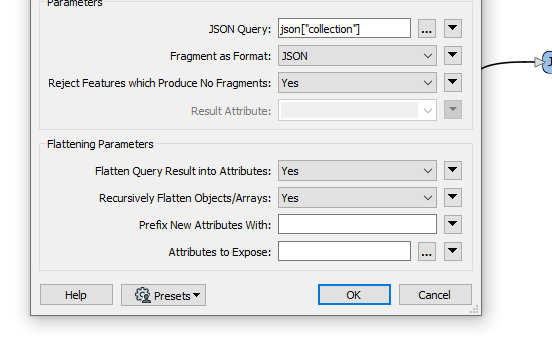
Hi,
I am new to JSON and I am trying to convert a JSON to a flat FME table.
In the workbench attached, I found a way, but I was wondering if there is a more
simple way.
My second question is: is there a way to convert this to a flat table without knowing the object attribute keys?
Jasper