Hi,
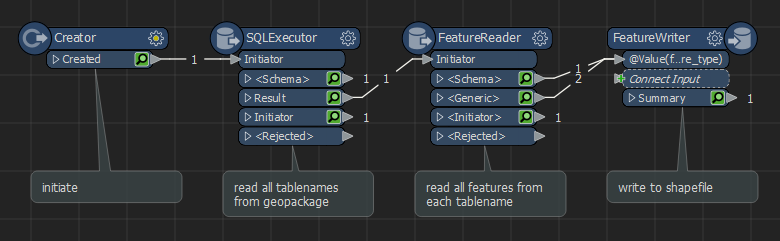
I would like to create a workspace that reads all tables that start with the same prefix. I then want to save the result per table as a shape file. If a table is modified by a add or remove an attribute, the workspace should pick this up automatically.
Is that possible?
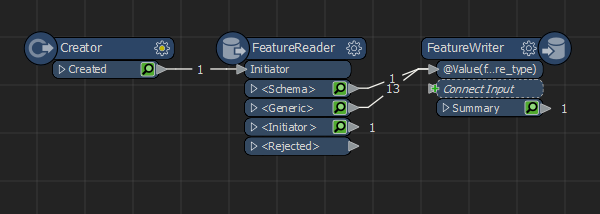
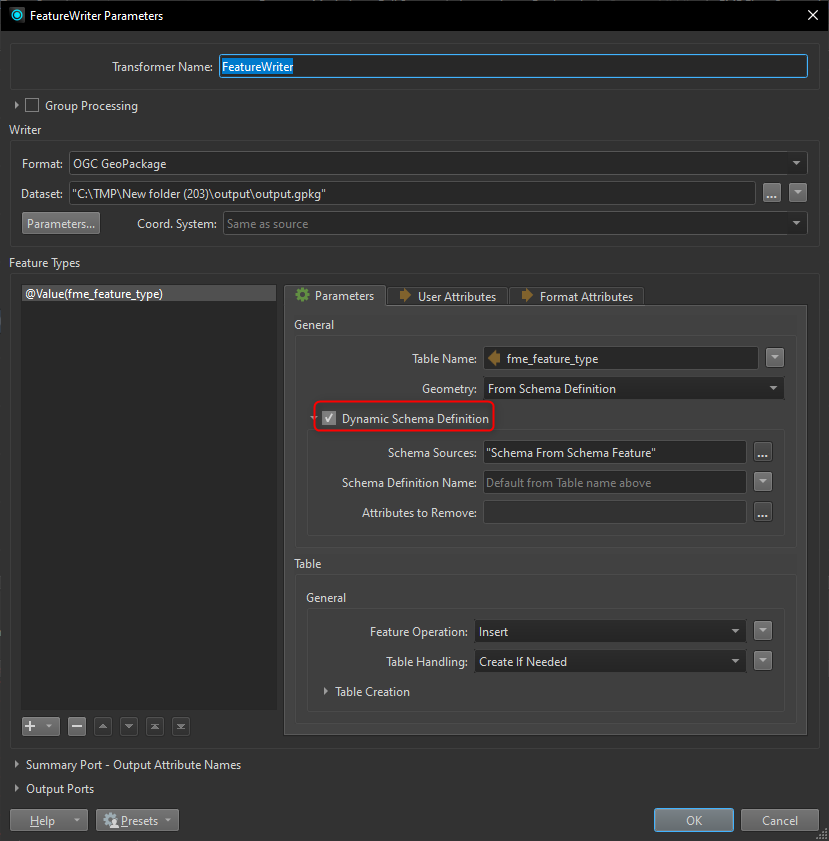
My first thought was to work with a dynamic reader, but then I get stuck that it will retrieve all tables, including in other schemas within the database.
The second approach is, I create a query that generates select statements and puts these statements in a text file. I then read the text file with a textline reader and install an SQLExecuter. That's all going well.
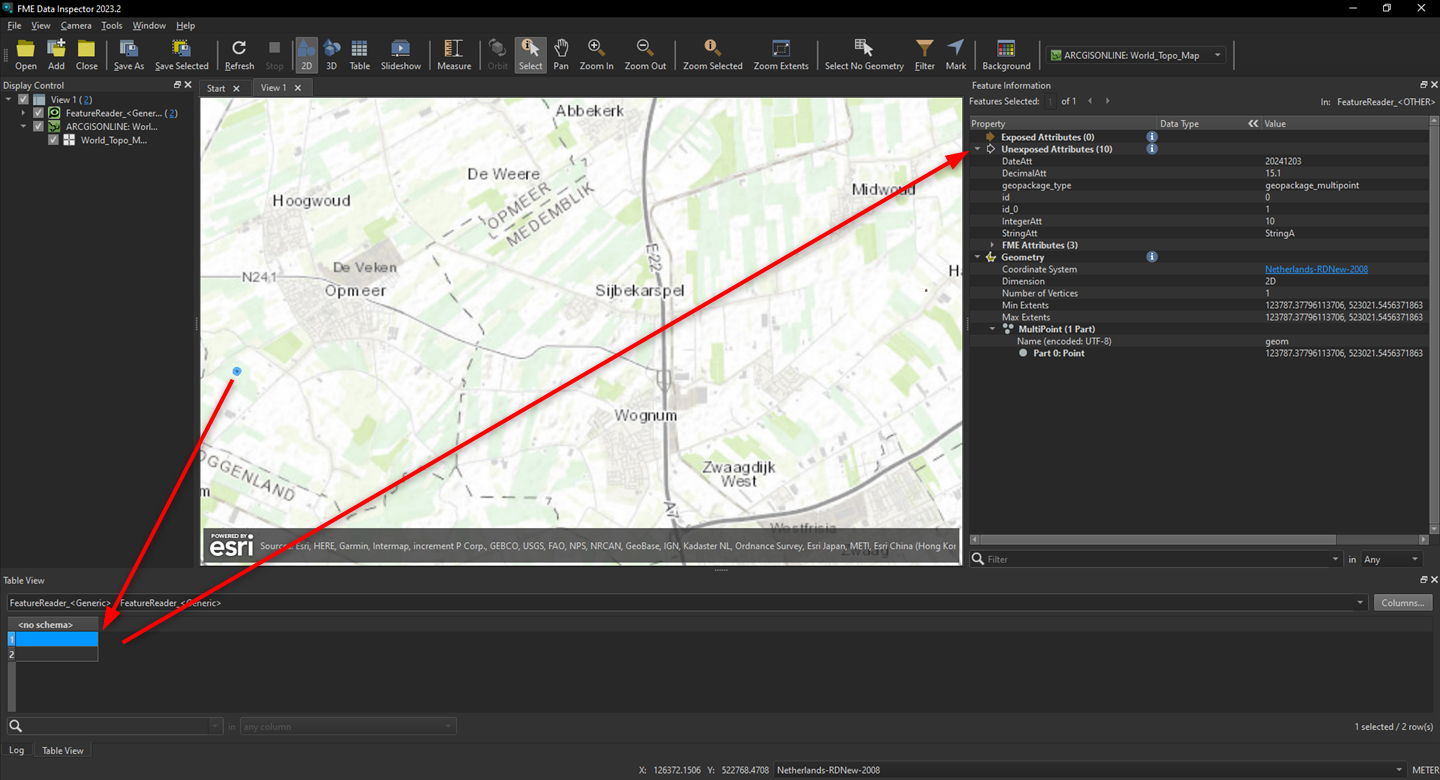
What I run into is that the SQLExceuter cannot automatically expose all attributes.