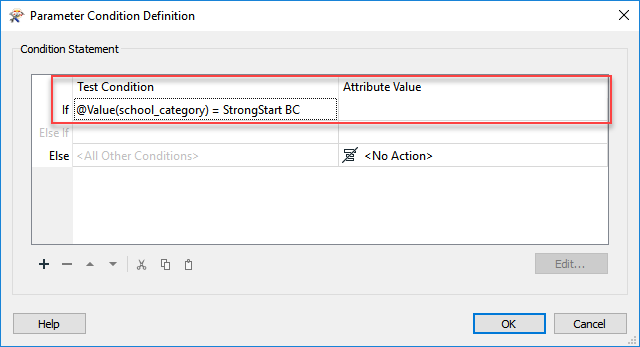
Hi all,
I am a newer user to FME, and I am using FME Workbench 2017.0.
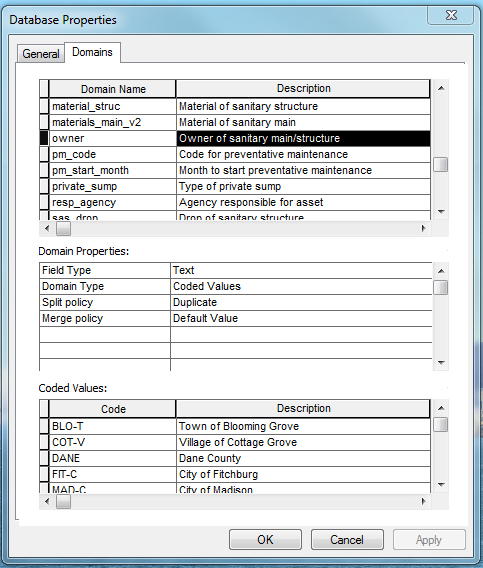
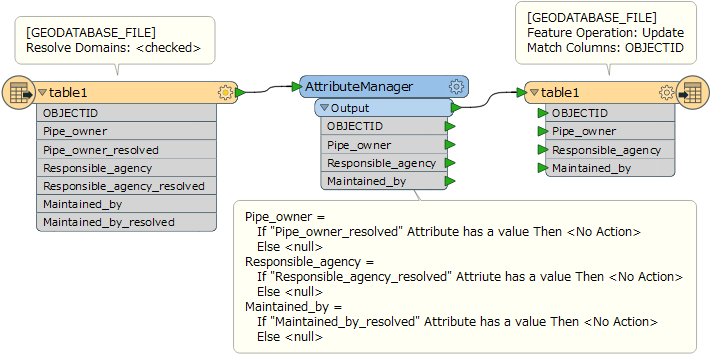
I have a new feature class that has coded domains. The data being input into the new feature class is coming from a feature class in an old MDB. I would like to delete attribute values from each field that does not have values within their respective coded domains, and they can either be null or empty strings.
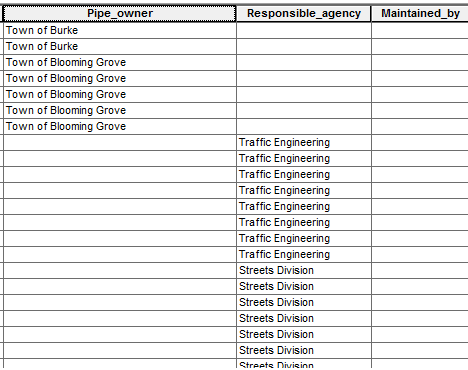
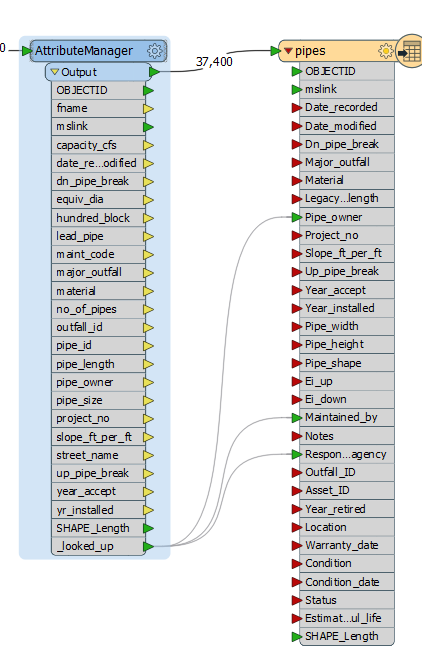
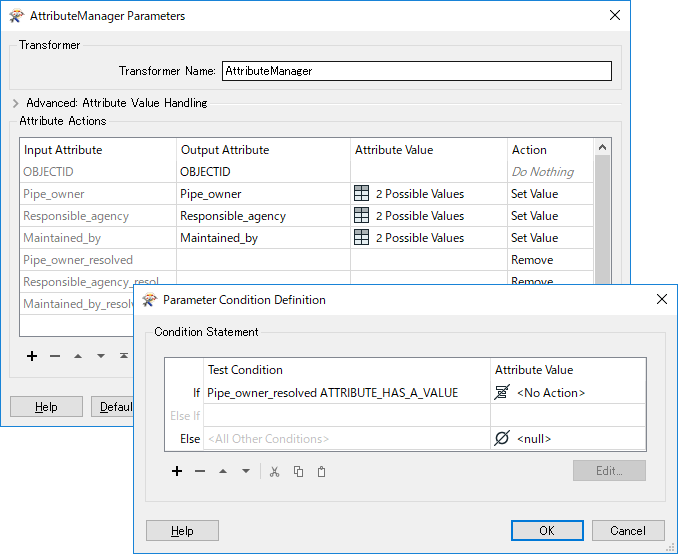
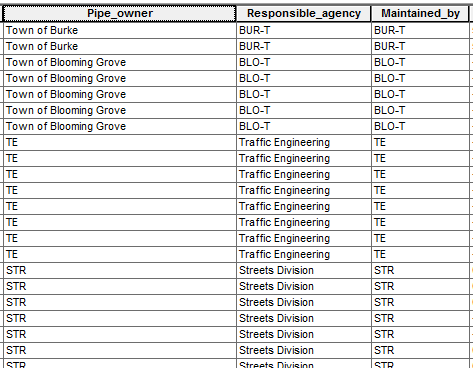
The picture shows an example of some of the data where you can see BUR-T does not exist as a coded value in responsible_agency or maintained_by, but it exists in pipe_owner. Or STR does not exist as a coded value in pipe_owner or maintained_by, but it exists in responsible_agency. I used AttributeValueMapper to get to this point.
Note: I have tried making a query to delete values with char_length < #, deleting uppercase values, and etc., and those did not seem to work because the 'Town of Burke' and 'Streets Division' values are still recognized as their codes, so they are subsequently deleted when the program is executed.
Any help would be appreciated. Thank you!